一、推荐系统概要
✨文章摘要(AI生成)
概述推荐系统核心概念、链路流程与A/B测试机制。
推荐系统基本概念
可以将一个推荐系统简单地理解为给用户推荐实体或非实体物品的系统。其任务是根据用户和物品的特征,使用某种或某些推荐算法预测任意用户对任意物品的兴趣得分,并按照预测的得分顺序,将排在前列的物品展示给用户。
以小红书为例,物品为小红书笔记,后续统一使用物品进行描述。
转化流程
根据不同公司的不同产品,一般有不同的转化流程。流程中的动作意味着用户对物品感兴趣,这些动作意味着用户和物品产生了交互,可以作为推荐系统使用的推荐依据。转化流程一般分为三步,下图以小红书为例: 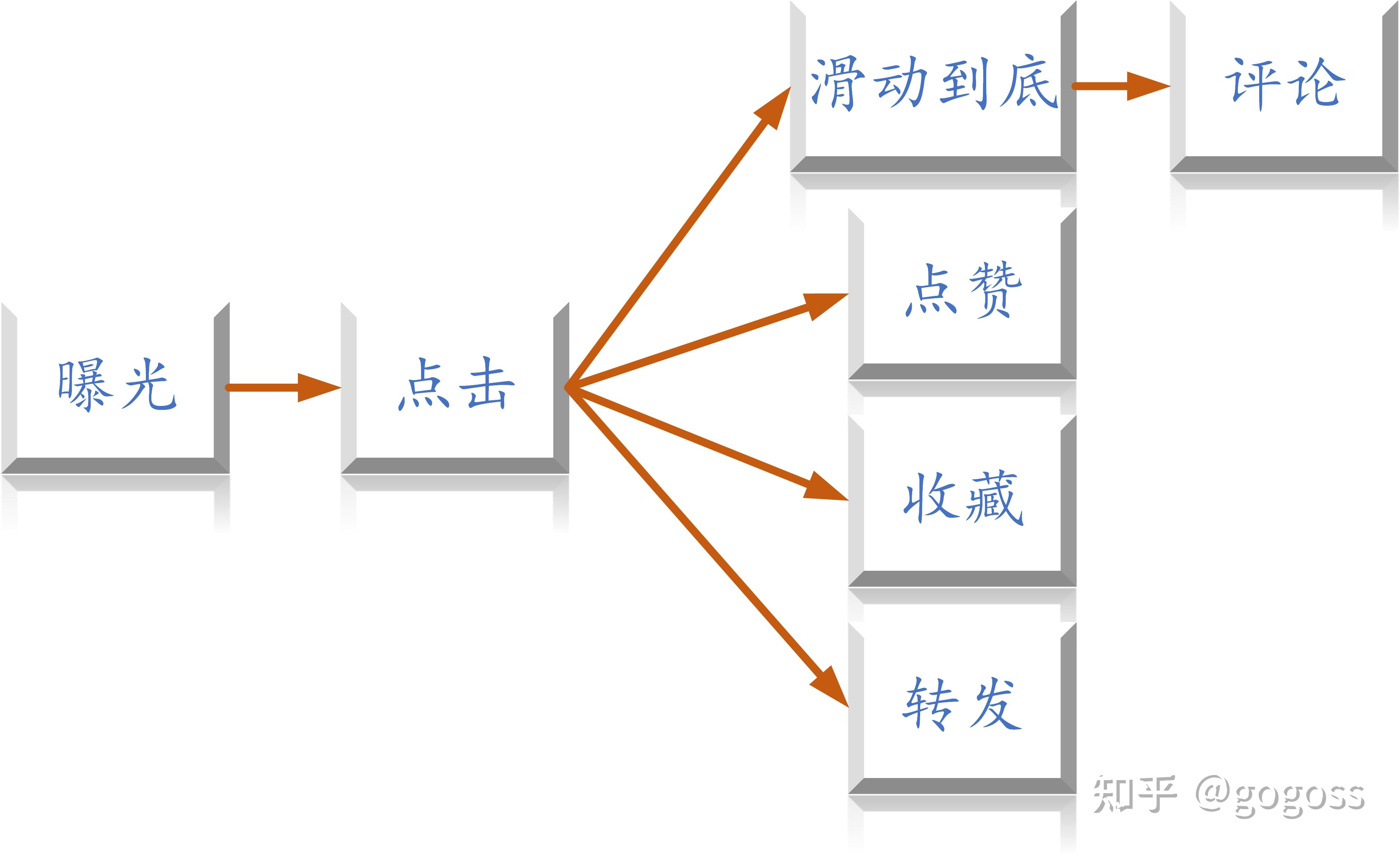
抖音没有点击流程
常见的推荐系统评测指标
| 消费指标(短期消费指标) | 北极星指标(长期消费指标) |
|---|---|
| 基于点击的指标:点击率 | 基于用户规模:日活用户数(DAU)、月活用户数(MAU) |
| 基于反馈的指标:点赞率、收藏率、转发率 | 基于消费用户:人均使用推荐时长、人均阅读笔记数量 |
| 基于特定产品的指标:阅读完成率(文章) | 基于发布用户:发布渗透率、人均发布量 |
阅读完成率=滑动到底次数/点击次数 X f(笔记长度)归一化 其它指标可通过简单除法计算 优质的内容池是平台的核心竞争力 通过冷启动实现激励发布 北极星指标都是线上指标,不能通过离线实验获取
消费指标并不是推荐系统追求的根本目标,考察的关键应该放在北极星指标上。只关注追求极致的消费指标提升,最直接的影响就是导致推荐给用户的物品都是相似或相同的,显著减少了推荐的多样性,用户很难接触到感兴趣但新鲜的物品,长久以往用户活性降低,用户不断流失。在实践中,消费指标降低但是北极星指标提升也被认为是一种正向的趋势。
推荐系统的实验流程
实验流程:离线实验 → 小流量A/B测试 → 全流量上线
离线实验:收集历史数据在其上做模型训练和测试,算法没有部署到产品中,没有跟用户交互。 小流量A/B测试:把算法部署到产品中,设置实验组与对照组使用新旧策略,算法与部分用户做交互。 全流量上线:A/B测试的新策略优于旧策略,就加大交互的用户流量,最后推全。
推荐系统的链路
推荐系统目标:从几亿物品中选取几十个物品推荐给用户。 推荐系统的链路: 
召回:用多条召回通道(协同过滤、双塔模型、关注的作者等)快速召回物品,每条通道取回几十个物品,一共取回几千个物品。 粗排:用小规模神经网络,给几千篇物品打分,按照分数排序做截断,保留分数Top几百的物品。 精排:用大规模神经网络,给粗排选出的几百篇物品重新打分排序,之后可以选择是否做截断,小红书的精排不做截断,所有精排后的物品带着分数进入重拍。 重排:根据精排分数和多样性分数从几百篇物品中挑选几十篇,依规则打散并插入广告和运营物品,根据生态再调整排序。
召回通道实际上就是实现召回的模型方法,第二章节会详细介绍协同过滤、双塔模型和其他召回通道。
推荐系统的AB测试
召回团队实现了一种新的召回通道,离线实验结果是正向的,下一步就需要做线上的小流量A/B测试。A/B测试启到如下作用:
- 考察新的召回通道对线上指标的影响;
- 测试选择模型的最优参数。
随机分桶
A/B测试需要设置对照组和实验组,对照组和实验组的实验通过随机分桶来实现。不妨设有全部
- 首先使用哈希函数将用户ID映射成某个区间内的整数,然后把这些整数均匀随机分成 个桶;
- 可以取其中若干个桶作为多个实验组采用不同的召回通道,再另取一个新桶为对照组使用原策略;
- 计算每个桶的业务指标;
- 如果某个实验组显著优于对照组,则说明对应的策略有效,值得推全。
 从统计学角度出发,如果样本足够大,可以认为各个桶的特征相同。
从统计学角度出发,如果样本足够大,可以认为各个桶的特征相同。
分层实验
互联网大厂这种信息流公司有很多的团队和部门,需要同时负责推荐系统(召回、粗排、精排、重排)、用户界面、广告等业务的A/B测试。此时会遇到用户流量不够用的情况,分层实验是一项很好的举措:
分层:分成召回、粗排、精排、重排、用户界面、广告等等多个层。 同层互斥:某召回实验占用召回层的
个桶,则其他召回实验只能用剩余的 个桶。目的是避免一个桶内用户同时被两个召回实验影响造成实验不可控的结果。 不同层正交:每层独立随机对用户做分桶,每层都可以独立使用全部桶的用户做实验。
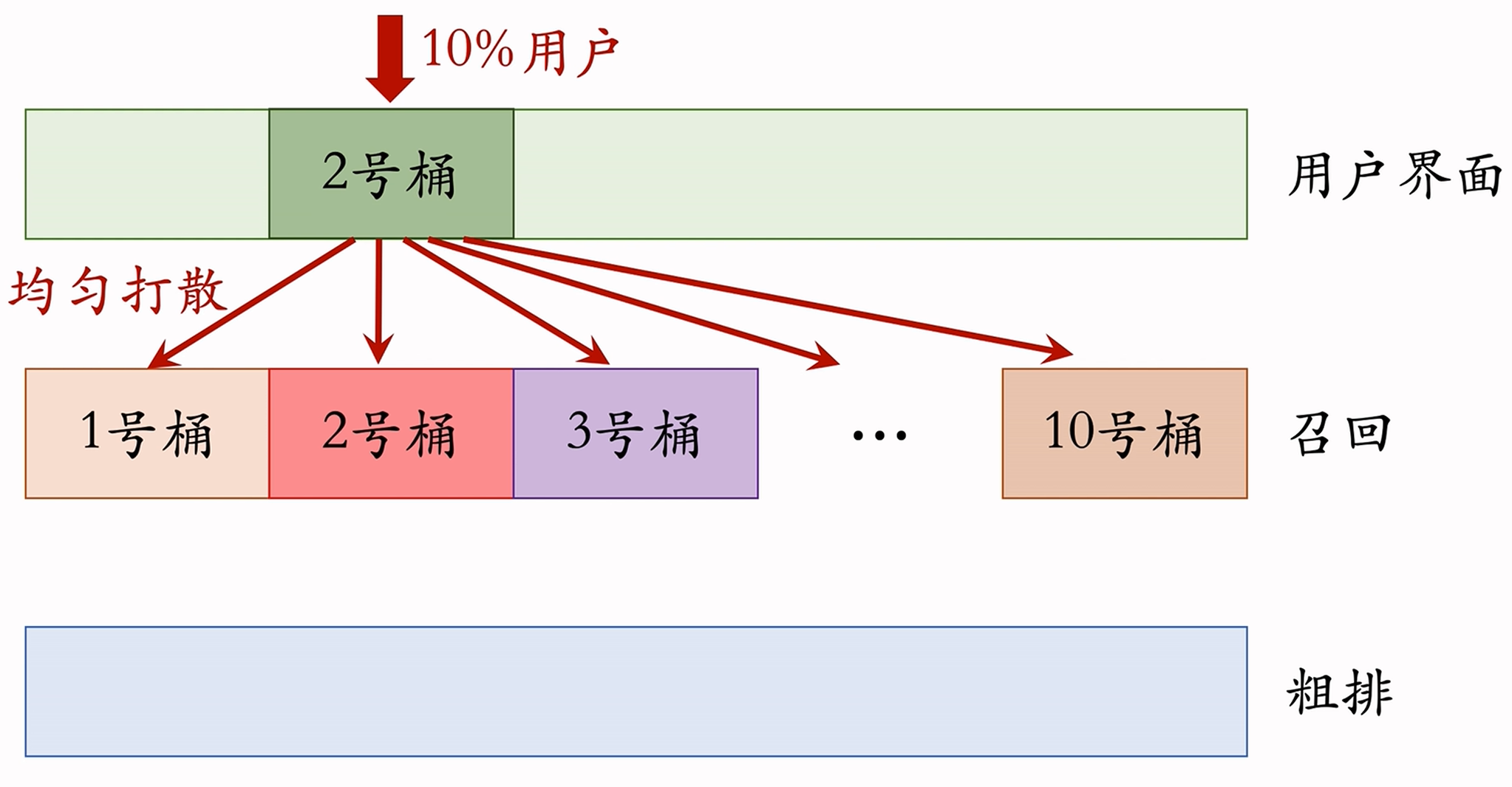 不同层之间的实验效果不容易相互增强或者相互抵消,因此允许一个用户同时受多层实验的影响。基于以上原理,不妨以召回和召回的下一层(粗排层)为例说明。假设该系统有
不同层之间的实验效果不容易相互增强或者相互抵消,因此允许一个用户同时受多层实验的影响。基于以上原理,不妨以召回和召回的下一层(粗排层)为例说明。假设该系统有
任意的召回桶
和粗排桶 满足 同层互斥:不同的召回桶 和 交集为 不同层正交:不同的召回桶 和粗排桶 的交集大小为
既然分层实验可以有效处理流量不足问题,那么是否存在所有实验都正交,则可以同时做无数组实验的情况呢?答案是否定的,原因如下:
- 同类的策略(比如召回层的不同通道)天然互斥,对于同一用户只能使用其中一种,故应该放在同层。同类的策略可能相互抵消或相互增强,互斥可避免同类策略相互干扰。
- 不同类的策略(比如添加召回通道和优化粗排模型)会通常不会相互干扰,可以做正交的两层。
Holdout 机制
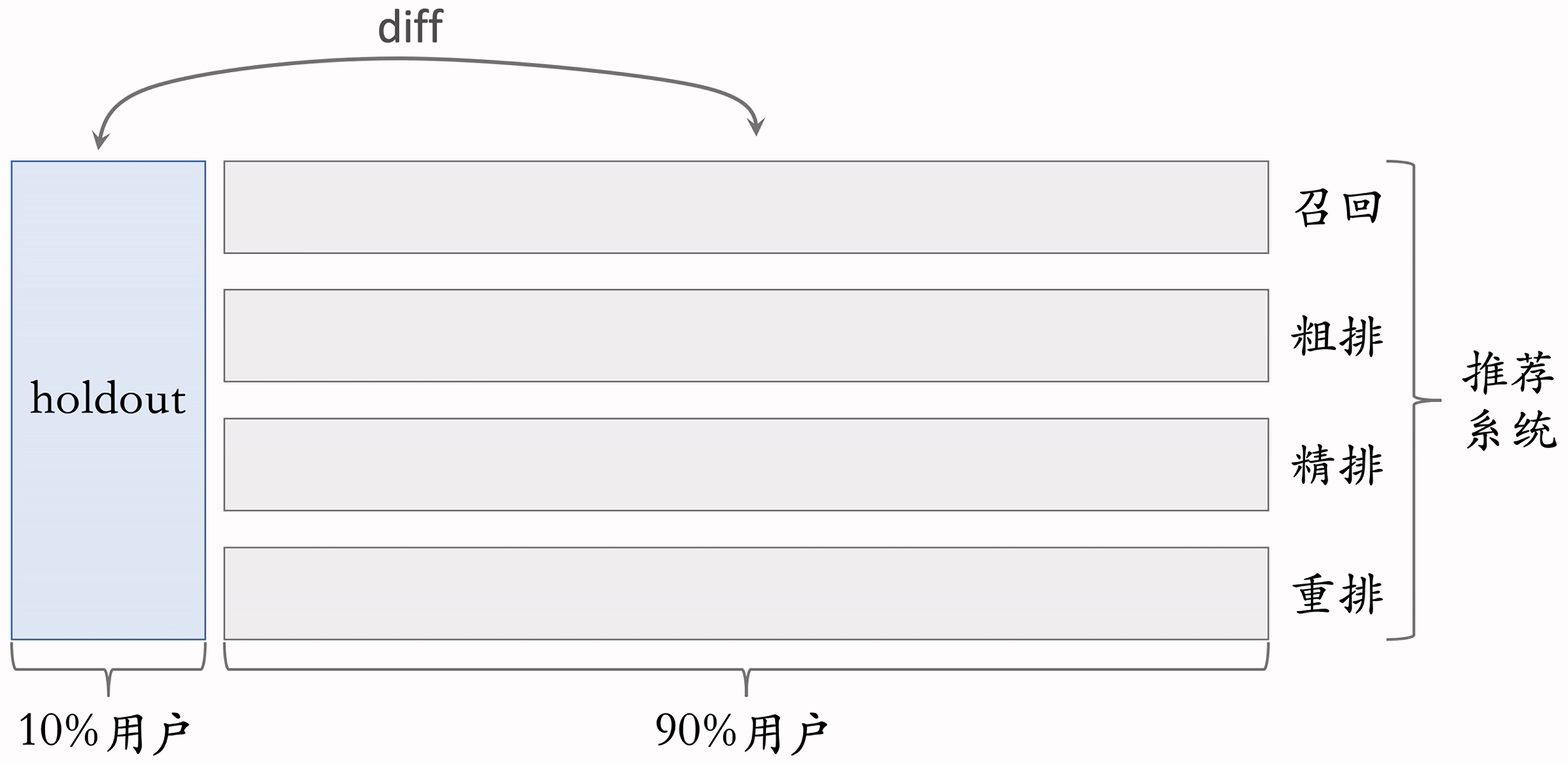
公司需要考察部门(如推荐系统)在一段时间内对业务指标的总体提升,需要每个实验(召回、粗排、精排、重排)独立汇报对业务指标的提升贡献,因此设置了Holdout机制,基本思想为:
- 取10%的用户作为Holdout桶,推荐系统使用剩余90%的用户做实验,两者互斥;
- 考察10%Holdout桶与90%实验桶的差异(需归一化)作为整个部门的业务指标收益;
- 每个考核周期结束之后,清除Holdout桶,让推全实验从90%用户扩大到100%用户;
- 重新随机划分用户,得到Holdout桶和实验桶,开始下一轮考核周期;
- 初始的新Holdout桶与实验桶的各种业务指标的差异接近0,随着召回、粗排、精排、重排实验上线和推全,差异会逐渐扩大。
实验推全和反转实验
实验推全:在Holdou机制基础上,观测到某个策略对某个桶有明显提升,关闭A/B测试,将策略推全到整个90%用户上。需要在召回层之前新建一个推全层,该层与其他层正交。 反转实验:为尽快推全新策略和长期观测实验指标,需要设立反转实验。在实验推全的新层中设立一个旧策略的桶,长期观测实验指标。
- 譬如点击、交互这些指标会立刻受到新策略的影响,而譬如留存这类指标具有滞后性,需要长期观测。
- 同时,实验观测到显著收益后需要尽快推全全新策略,腾出桶给其他实验使用或基于新策略尽快尽快进行开发。
如下图所示,推全层中推全新策略的桶和使用旧策略的反转桶是互斥的。新推全层是与Holdout桶无关的,考核周期结束后清除Holdout桶不会影响反转桶。反转实验结束后关闭反转桶,真正做到推全到100% 用户上。 