三、排序
✨文章摘要(AI生成)
梳理推荐排序体系,涵盖多目标模型、MMoE、融分与粗排三塔。
前面介绍过,虽然所用的神经网络的深度与规模不同,但粗排和精排都是对召回后的物品再进行排序的操作,总体上思想与框架相同。主要差异在于粗排模型参数量小、特征少、效果差一些,但是能起到快速筛选的作用,避免将几千篇笔记直接输入精排模型出现过大的计算代价。推荐系统链路如下 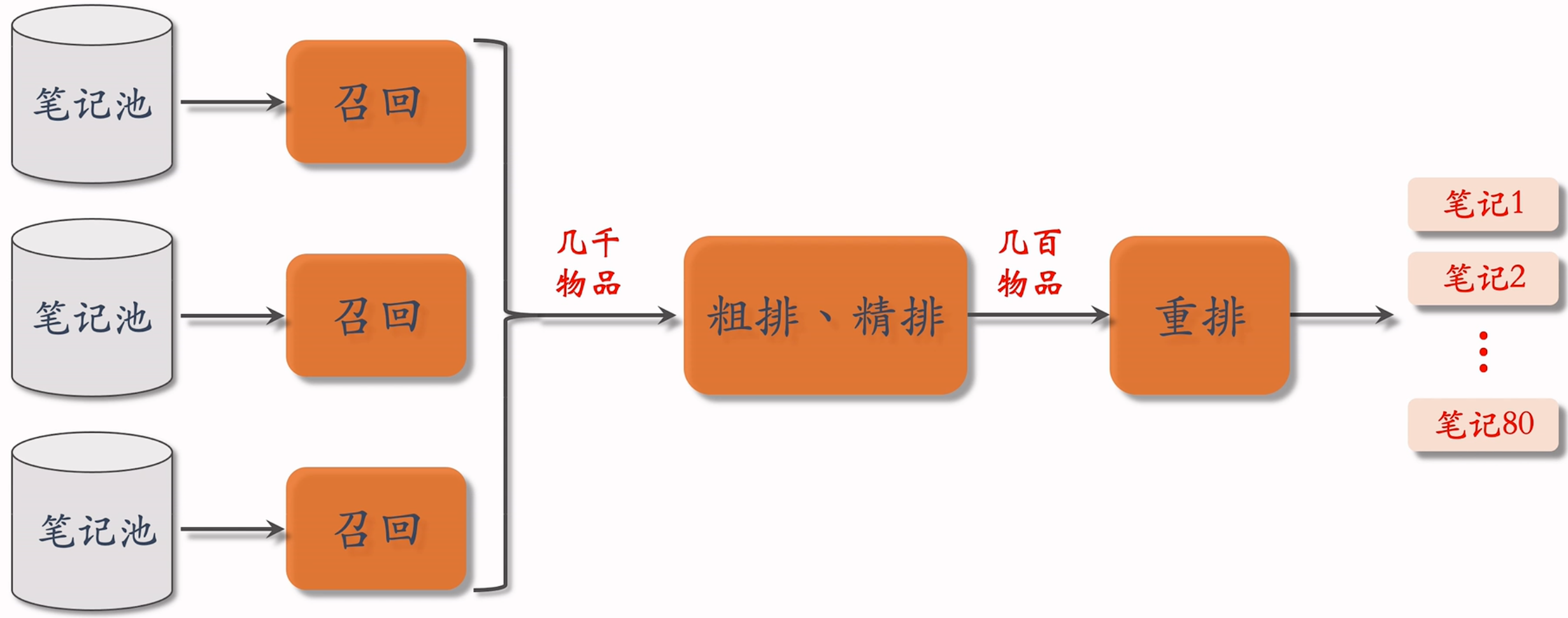
多目标模型
用户与笔记的交互
在介绍转化流程中有说过,用户与物品的交互可以作为系统推荐的依据。在小红书中,对于每篇笔记,系统记录曝光次数、点击次数、点赞次数、收藏次数、转发次数,由此计算得到消费指标,可以衡量一篇笔记受欢迎的程度:
1. 点击率 = 点击次数 / 曝光次数;(注意点击率这里是曝光次数)
2. 点赞率 = 点赞次数 / 点击次数;
3. 收藏率 = 收藏次数 / 点击次数;
4. 转发率 = 转发次数 / 点击次数。(转发很少,但是很重要)
排序的依据
在得到消费指标后,那么如何实现衡量物品受欢迎程度呢?前面介绍在召回中,模型利用用户和物品的多维特征属性(ID,画像等),通过计算得到用户对物品的兴趣分数。而在排序中的基本思想如下:
- 排序模型预估点击率、点赞率、收藏率、转发率等多种物品;
- 融合这些分数;(比如加权和,权重由A/B测试调整选出)
- 根据融合的分数做排序、截断。
多目标模型
工业界常用多目标模型作为排序模型,其输入包括各种各样的特征,模型基本结构如图: 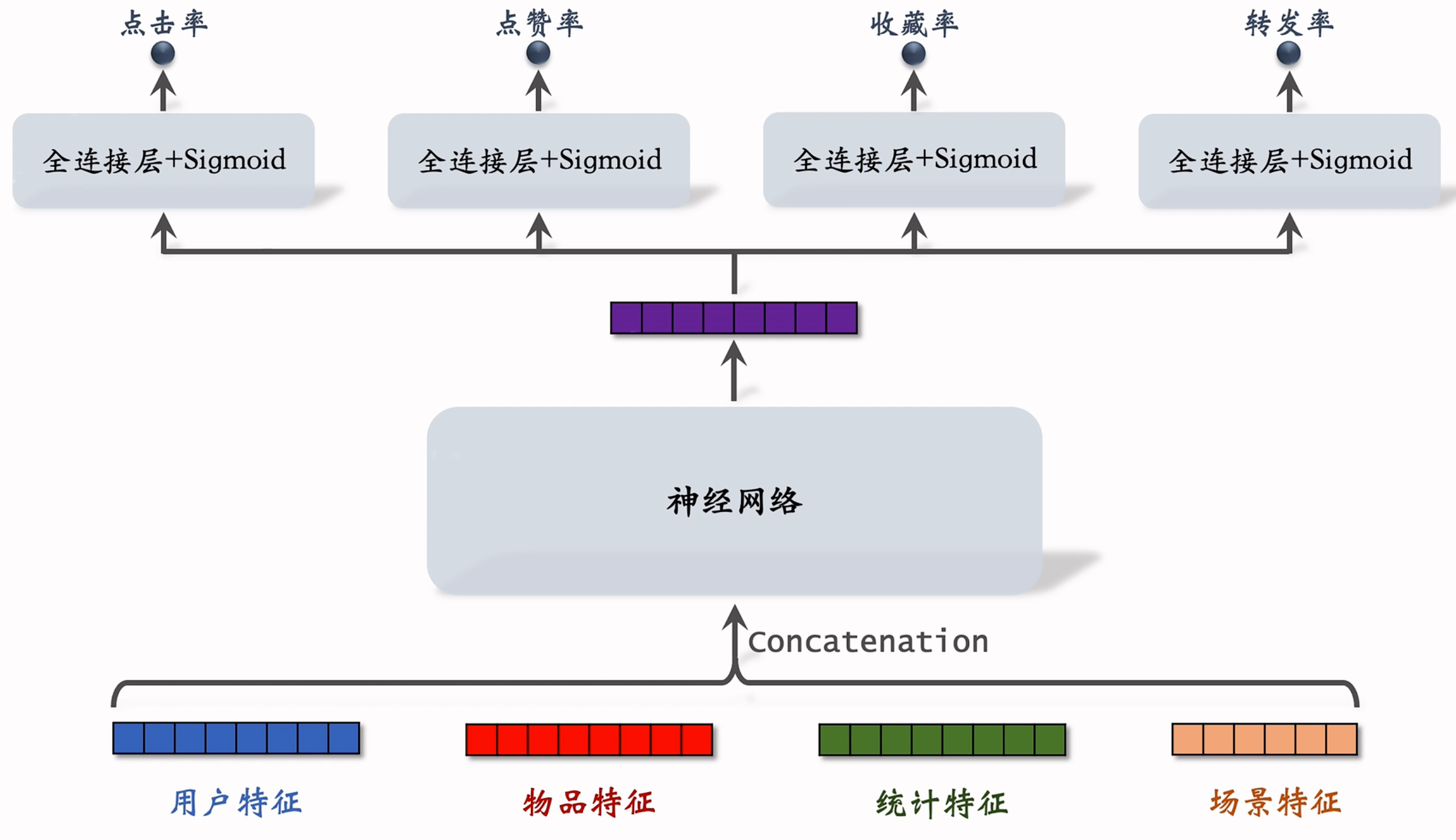
- 统计特征包括用户和物品的统计特征,比如用户在30天内点赞了多少篇笔记、候选物品在30天内获得了多少次曝光机会等;
- 场景特征包括用户所在的时间、地点等,比如候选物品在不同的城市、季节以及节假日影响,用户对其有完全不同的兴趣程度;
- 在精排中,这里的神经网络被称为 shared bottom ,是非常大、结构非常复杂的神经网络。
模型训练
 通过上述模型可以得到譬如点击率、点赞率、收藏率、转发率的预估值,不妨设这些预估值为
通过上述模型可以得到譬如点击率、点赞率、收藏率、转发率的预估值,不妨设这些预估值为
- 总的损失函数:$$\sum_{i=1}^4 \alpha_i\cdot CrossEntropy(y_i,p_i)$$其中超参数
是各个损失的权重。 - 对损失函数求梯度,做梯度下降更新参数。
而在训练中,也存在困难,最大的问题就是类别不平衡:
- 每100次曝光,约有10次点击、90次无点击;
- 每100次点击,约有10次收藏、90次无收藏。
显然,负样本的数量要远远多于正样本。常见的解决方案是进行负样本降采样(down-sampling):
- 保留一小部分负样本,让正负样本数量平衡;
- 减少了负样本数量,节约计算。
预估值校准
在模型输出各个指标预估值之后,需要先进行预估值校准,才能做后续的排序。主要原因在于:
- 以点击率为例,设正样本、负样本数量为
和 ; - 真实点击率:
(期望)。 - 对负样本做降采样会抛弃一部分负样本, 设
为采样率,则训练时使用了 个负样本; - 预估点击率:
(期望),显然由于负样本变少,分母变小,导致预估的点击率大于真实点击率
实际上预估值校准就是希望通过函数调整预估值,使得其能与真实值一致,根据上述两个点击率的等式可得对点击率预估值的校准公式为:
- 对于预估点击率
,等式右边的分子、分母同时除以 得到 ; - 等式两边同乘以等式右边的分母得
; - 展开等式左边的括号并移项得
; - 所以两边同除以系数得到
,也就是 ; - 现在将上一步中由预估点击率推导的
和 的关系式代入真实点击率公式 ,得到 ; - 对该公式上下同除以
、乘以 后整理得到校准公式: ,推导完毕。
可以思考一个问题,如果只做排序,校准与否不会影响排序的结果,那校准的意义在于什么呢?可能存在以下的原因:
- 以点击率为例,如果只是单纯优化点击这一项,通过降采样后各个物品的点击率的相对顺序不会变化,不做校准不会影响;
- 但是多目标模型涉及到多个指标结果的相乘或计算,而且多目标任务不校准无法统一量纲,所以必须进行校准;
- 另外在广告系统中,点击率需要参与广告计费的计算,必须需要校准后的精确值,当然校准方法也不仅限于预估值校准了。
Multi-gate Mixture-of-Experts
MMoE模型
MMoE 模型是对经典多目标模型的改进,它的基本思想就是对于不同的目标,在融合特征之后,先利用“专家”得到多个表征向量,同时分别利用神经网络得到不同的权重,最后对向量做加权平均输出预估值,具体模型架构如下图所示: 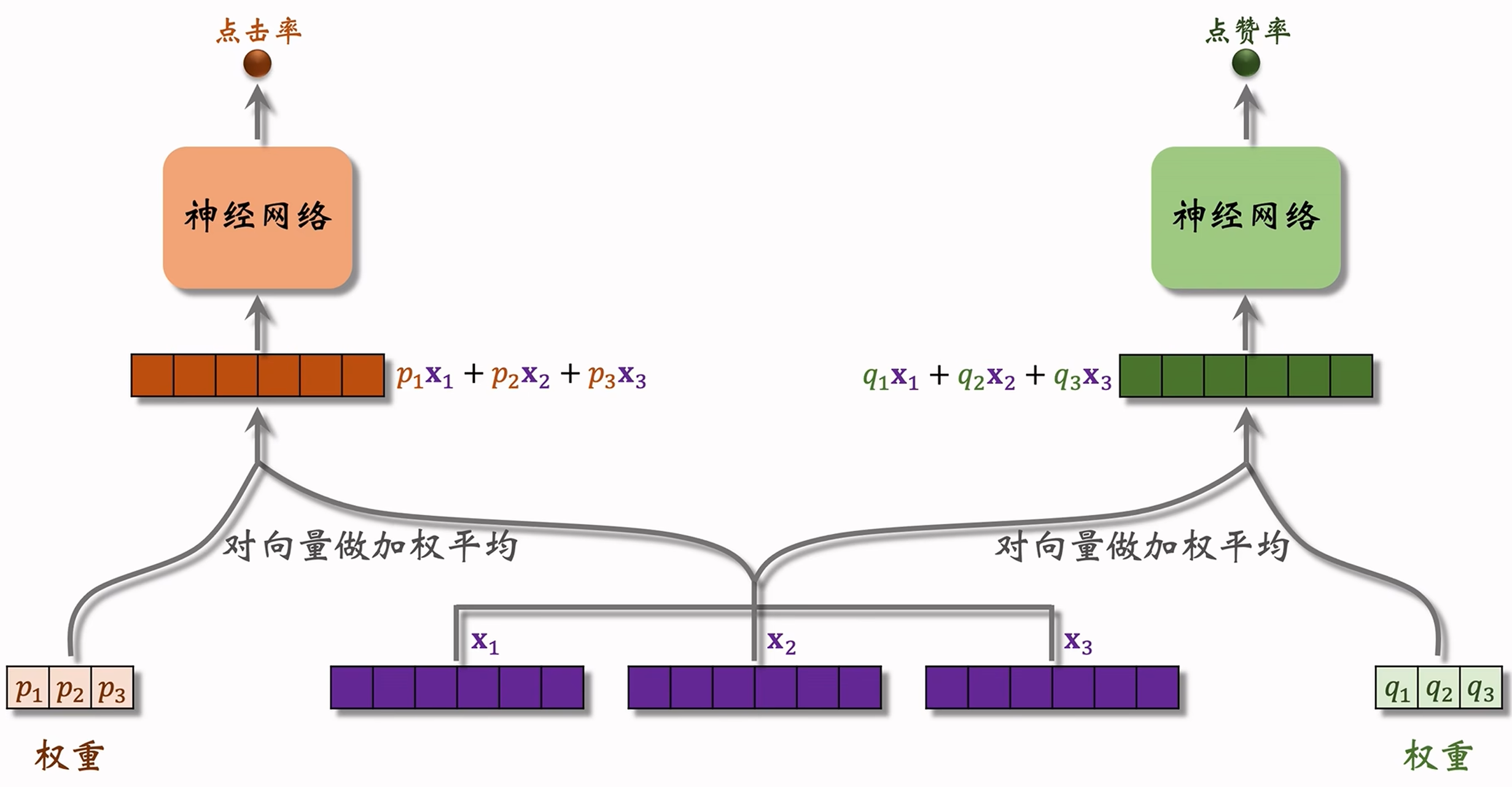
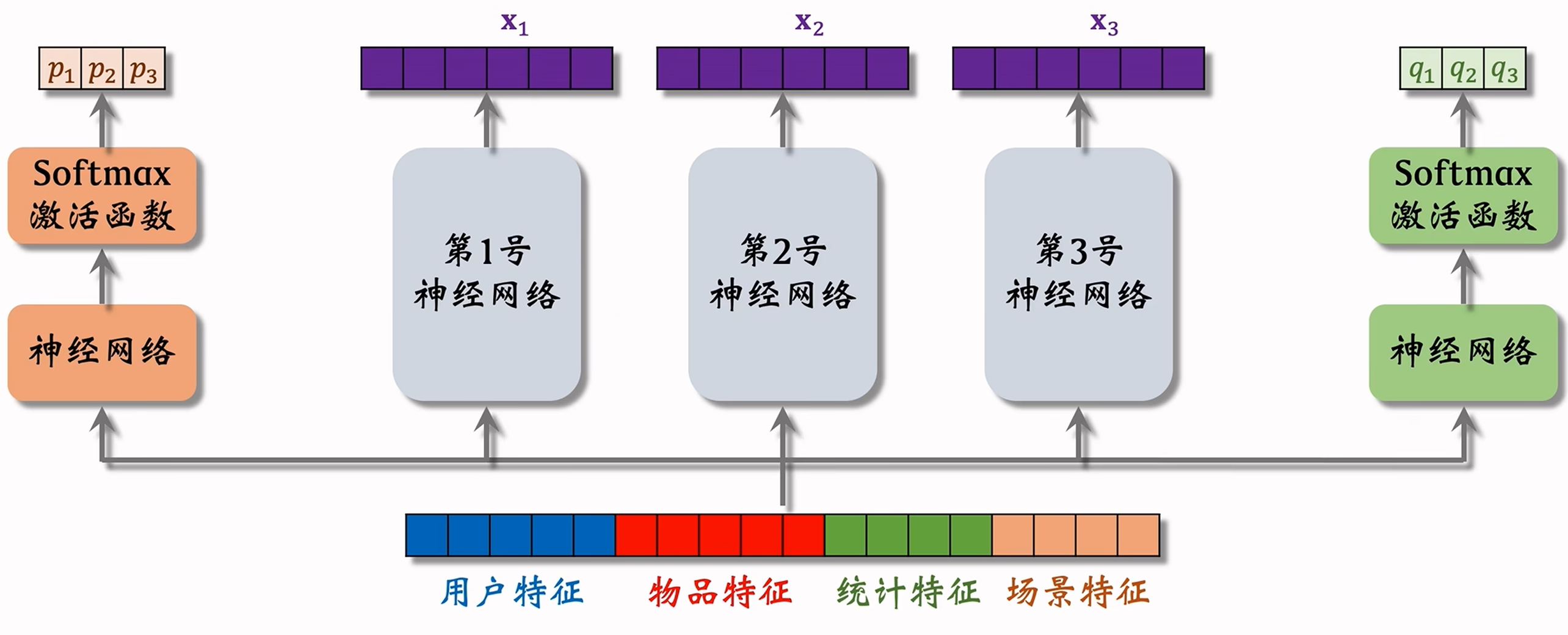
- 图中第1、2、3号神经网络就是该模型的三个“专家”(experts),专家数是超参数,在实际训练中多会尝试四个和八个的情况,这些专家网络的参数不共享;
- 如果有
个专家,则会输出 个向量 ,那么计算权重时每个 Softmax 的输出也都是 维向量,作为针对每个专家网络输出向量的权重; - 对于多个目标就需要对应数量的神经网络组合来计算不同权重和预估值。
极化现象
实践中,使用 Softmax 激活函数会不可避免的出现极化现象(Polarization):
- 极化(Polarize):Softmax 的输出只有一个接近 ,其余接近 ;
- 譬如在介绍 MMoE 模型的示意图中,假设左边的 Softmax 输出是
,相当于后续的预估值计算时只使用了第三号神经网络输出的向量;假设右边的 Softmax 输出是 ,相当于只使用了第二号神经网络。那么第一号神经网络在模型的训练中没有起到任何作用,相当于它“dead”了,使用 Mixture-of-Experts 的意义也就失去了。
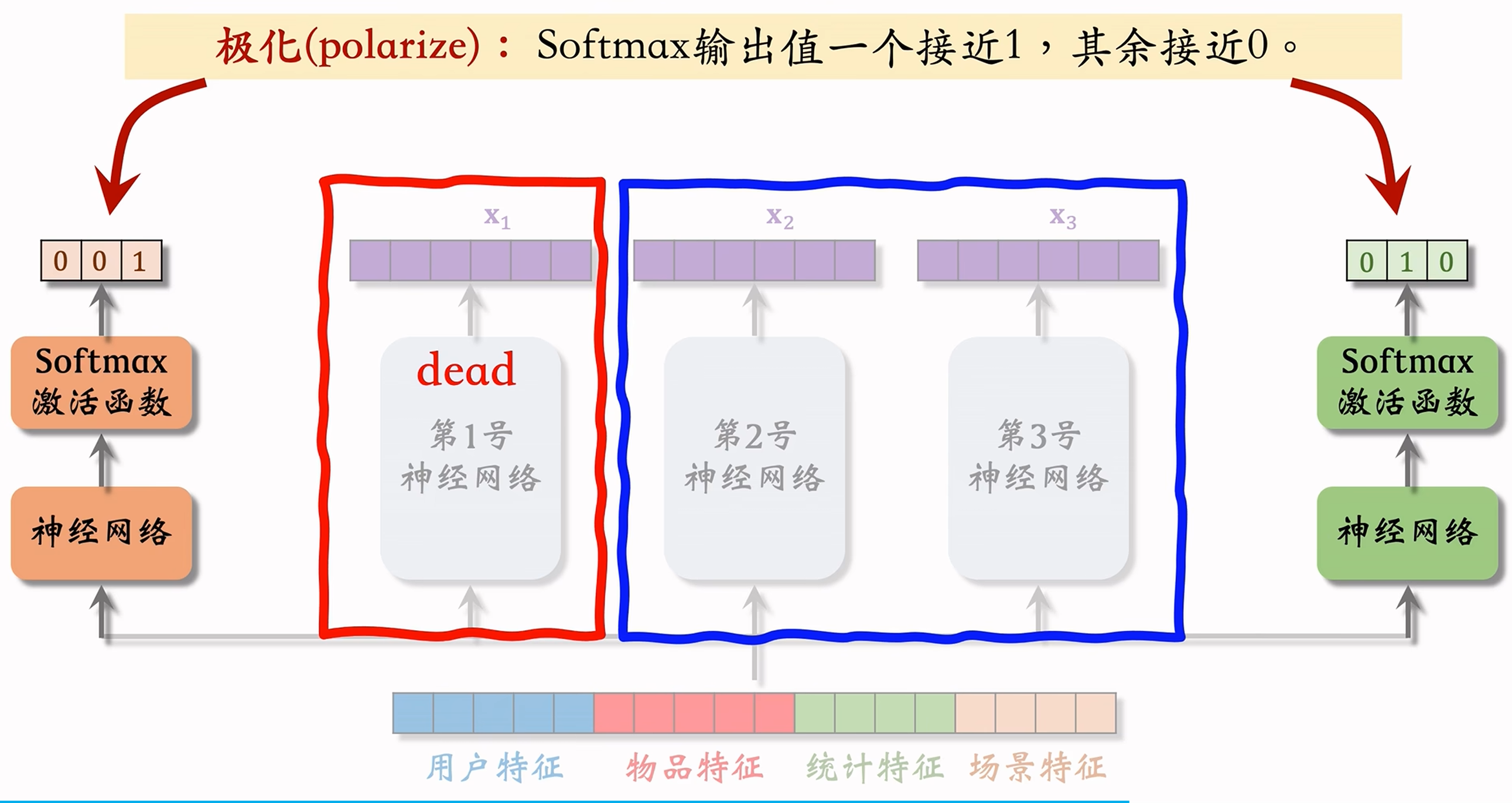
解决极化问题的基本方案就是在训练时,对 Softmax 的输出使用 Dropout:
- Softmax 输出的
个数值被 Mask 的概率都是10%,意味着每个专家被随机丢弃概率都是10% - 假设发生极化现象,并且极化的元素被Mask,会导致预测的结果特别差。为了让预测的结果尽量准确,神经网络会尽量避免发生极化现象,
预估分数融合
通过多目标模型,我们得到了点击率、点赞率、收藏率等的预估值
2. 点击率乘以其他项的加权和:  3. 海外某短视频APP的融合公式:
3. 海外某短视频APP的融合公式:
4. 国内某老铁短视频APP的融合公式(Ensemble sort): (1) 根据预估时长
5. 某电商的融合公式: (1) 电商的转化流程:曝光
视频播放建模
前面介绍了对于图文笔记这类排序的主要依据,包括但不仅限于点击、点赞、收藏、转发、评论等。而在视频的排序依据还有播放时长和完播,一般对于视频来说,这两个指标的重要性远高于其他指标。
视频播放时长
视频的播放时长是连续型变量,但是直接用回归拟合播放时长效果并不好。建议使用 YouTube 的时长建模,这里假设有一个计算排序预估值的多目标模型,先不考虑点击率等指标,仅研究播放时长: 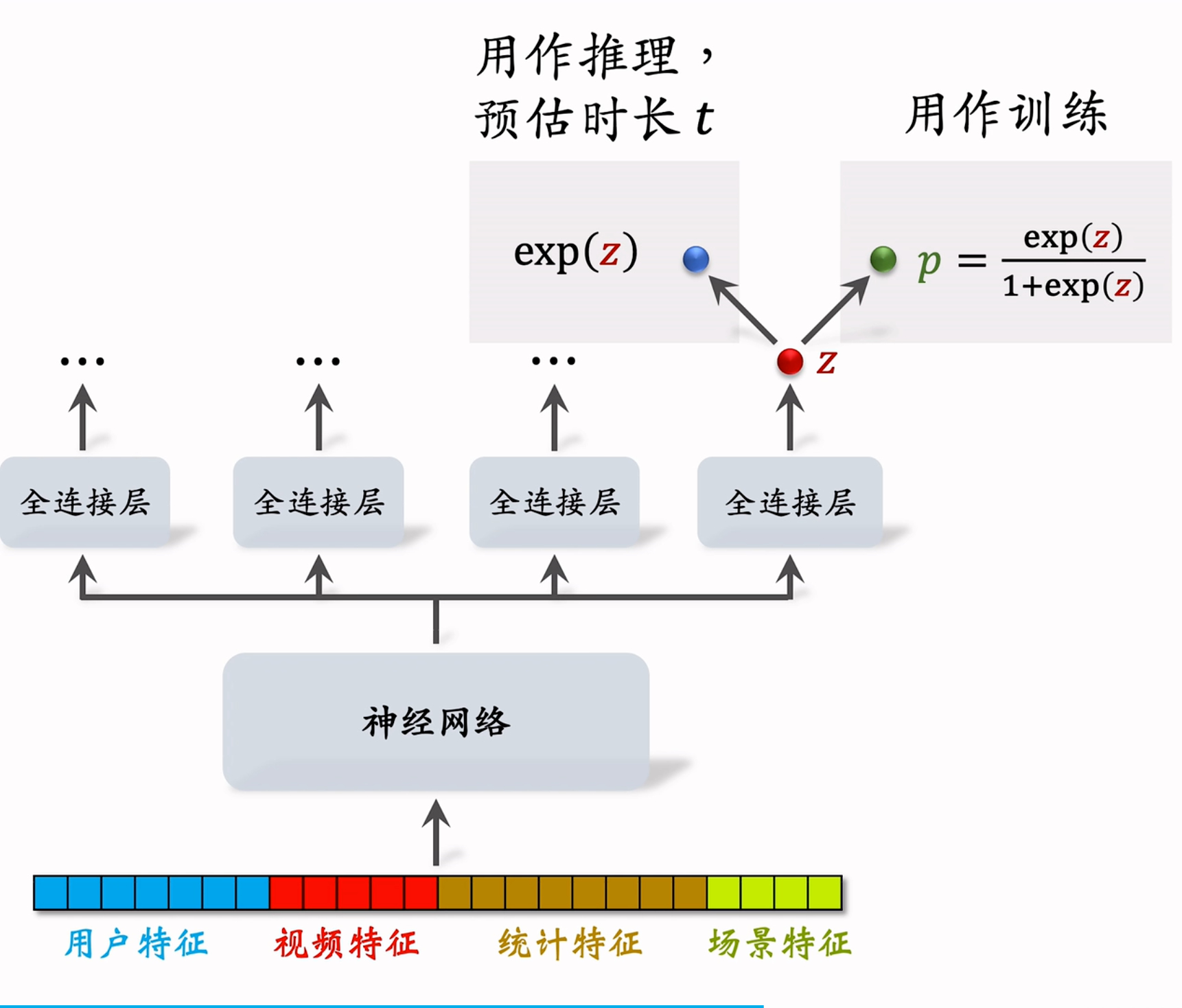
- 不妨设模型最后的全连接层输出一个预估值
,对 做 sigmoid 变换得到 ; - 模型的训练目标是让
拟合 ,其中 为真实视频播放时长,使用交叉熵损失 ; - 注意观察
和 的表达式,显然如果 则 ,所以在进行推理时, 就是对播放时长 的预估; - 最后,将
作为融分公式的一项。
视频完播率
对视频完播率的建模方法主要有回归和分类的两种方法,基本思想概括为:
- 回归方法:用预估播放率
拟合实际播放率 ,使用交叉熵损失 做训练,模型的输出 是预估完播率。 - 二元分类方法:定义完播
的时长作为完播指标,做二元分类训练模型(播放> (正样本)vs播放< (负样本)),模型输出 表示 。
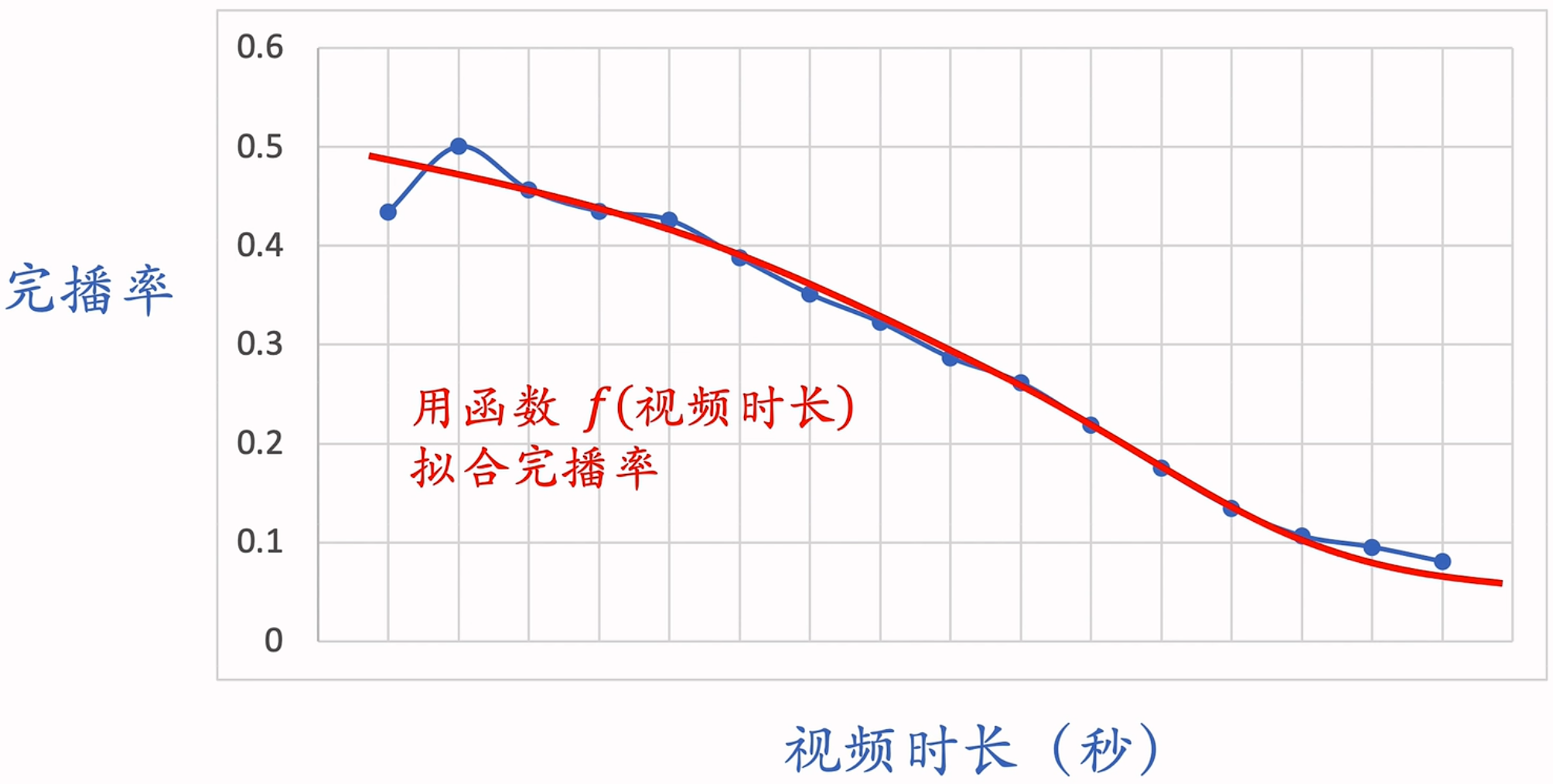
在实践中,我们不能直接将预估的完播率用到融分公式中。原因在于视频的时长越长,它的完播率越低,模型训练没有考虑视频时长的影响,不能平等对待长短视频。因此,需要先做如下处理:
- 线上预估完播率,然后做归一化调整:
- 将
作为融分公式中的一项。
排序模型的特征
特征类别
在召回和排序中,都需要用到用户和物品的多维特征,主要包括:
| 特征类别 | 特征描述 |
|---|---|
| 用户画像 (User Profile) | 1. 用户ID(在召回、排序中做embedding,常用32维和64维); 2. 人口统计学属性:性别、年龄; 3. 账号信息:新老、活跃度等;* 4. 感兴趣的类目、关键词、品牌等。 |
| 物品画像 (User Profile) | 1. 物品ID(在召回、排序中做embedding); 2. 发布时间(或者年龄);** 3. GeoHash(经纬度编码)、所在城市; 4. 标题、类目、关键词、品牌等; 5. 字数、图片数、视频清晰度、标签数等; 6. 内容信息量、图片美学等(利用nlp、cv模型事先打分)。 |
| 用户统计特征 | 1. 用户最近若干时间的曝光数、点击数、点赞数、收藏数等; 2. 按照笔记图文/视频分桶;*** 3. 按照笔记类目分桶;**** |
| 笔记统计特征 | 1. 笔记最近若干天的曝光数、点击数、点赞数、收藏数; 2. 按照用户性别分桶、按照用户年龄分桶等; 3. 作者特征:发布笔记数、粉丝数、消费指标等。***** |
| 场景特征 (Context) | 随着推荐请求传来,不用从用户和物品画像中获取。 1. 用户定位GeoHash(经纬度编码)、城市; 2. 当前时刻(分段,做embedding); 3. 是否周末、是否节假日; 4. 手机品牌、手机型号、操作系统。****** |
- :新老、高低活用户的行为差距很大,模型需要针对做专门的优化;
** :一般小红书中笔记发布时间越久价值越低,尤其是与新闻舆论相关的时效性只有几天;
*** :例如最近7天,该用户对图文笔记的点击率、对视频笔记各自的点击率;
**** :例如最近30天,用户对美妆笔记的点击率、对美食笔记的点击率、对科技数码笔记的点击率;
***** :反映作者的受欢迎程度和作品的平均品质;
******:安卓和ios的指标差异特别大。
特征处理
对于不同类型的特征进行处理的方式如下:
| 特征类型 | 处理方式 | 特征描述 |
|---|---|---|
| 离散特征 | 做embedding | 1. 用户ID、笔记ID、作者ID等;(消耗内存较大) 2. 类目、关键词、城市、手机品牌。 |
| 连续特征 | 做分桶,变成离散特征 | 年龄、笔记字数、视频长度等 |
| 连续特征 | 其他变化 | 1. 曝光数、点击数、点赞数等数值做 log(1+x) 变换; 2. 转化为点击率、点赞率等值,并做平滑。 |
上表中的
变换针对长尾数据,可以处理异常值。当然,在做特征处理时,除了要考虑异常值还需要考虑特征覆盖率。
实际上,大多数特征无法覆盖100%样本(不写年龄、设置隐私权限等)。显然,提高特征覆盖率可以让精排模型更准,所以在特征处理时还需要考虑如何做缺失值的默认补全。
数据服务
省略召回服务器,重点关注排序服务器。主服务器收到用户请求之后,从中解析物品ID(召回结果中的几千个物品)、用户ID(一个用户)和场景特征(时刻、位置、手机型号以及操作系统...)。然后,排序服务器需要从三个数据源取回排序所需的特征,因为用户的数量只有一个,故用户画像可以存储较丰富的信息,而物品数量较多,故物品画像不应该存较大的向量。此外,用户和物品画像偏向静态,可以缓存在排序服务器本地,统计数据需要实时更新,故不应该放在排序服务器的本地。之后,排序服务器将这些特征打包发送给TensorFlow服务,得到针对每篇笔记的打分。最后,排序服务器利用融合的分数、多样性分数和业务规则做好排序,将排序最高的几十篇笔记返回给主服务器曝光给用户。 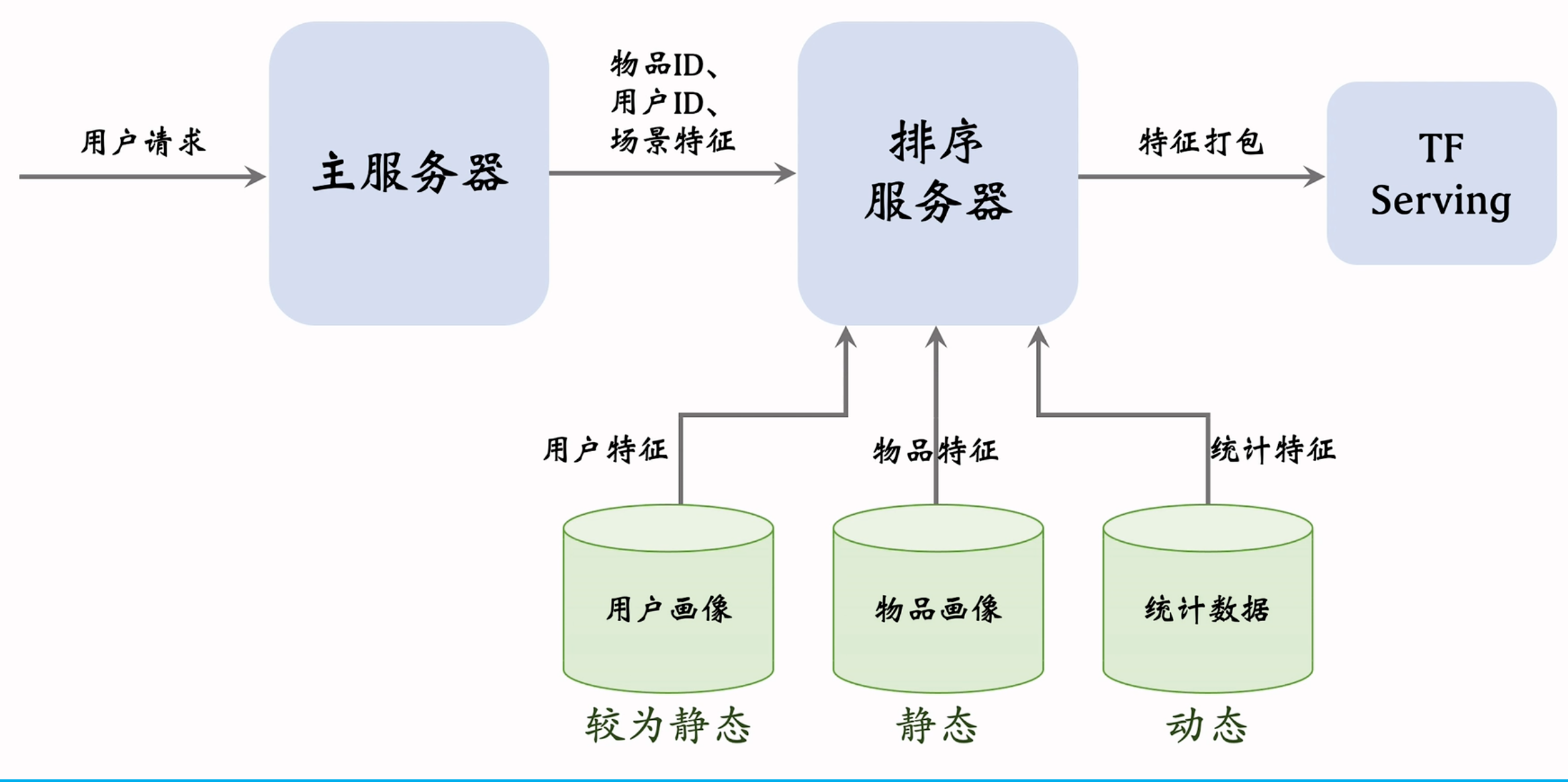
粗排模型
- 虽然本章内容不具体细分粗排和精排,但是前序内容主要还是描述精排模型。所以这节单独介绍粗排模型。
粗排 vs 精排
粗排是在精排之前进行快速初步筛选的操作,所以粗排和精排有存在一些区别:
| 粗排 | 精排 | |
|---|---|---|
| 任务 | 给几千篇笔记打分 | 给几百篇笔记打分 |
| 推理代价 | 单次推理代价必须小 | 单次推理代价很大 |
| 准确性 | 预估的准确性不高,但要足够快速 | 预估的准确性更高 |
精排 vs 双塔
回顾二、三章在召回和排序中主要使用的两个模型,它们的区别在于:
| 精排模型 | 双塔模型 | |
|---|---|---|
| 融合方式 | 前期融合:先对所有特征做concatenation,再输入神经网络。 | 后期融合:把用户、物品特征分别输入不同的神经网络,不对用户、物品特征做融合。 |
| 推理代价 | 线上推理代价大:如果有n篇候选笔记,整个大模型要做n次推理。 | 线上计算量小:用户塔只需要做一次线上推理,而物品表征通过线下计算事先存储在数据库中,物品塔在线上不做推理。 |
| 显然,双塔模型的预估准确性不如精排模型,后期融合适合快速做召回,而前期融合更适合做精准排序。 |
粗排的三塔模型
小红书的粗排模型是三塔模型,效果介于精排和双塔模型之间,模型架构如下图所示: 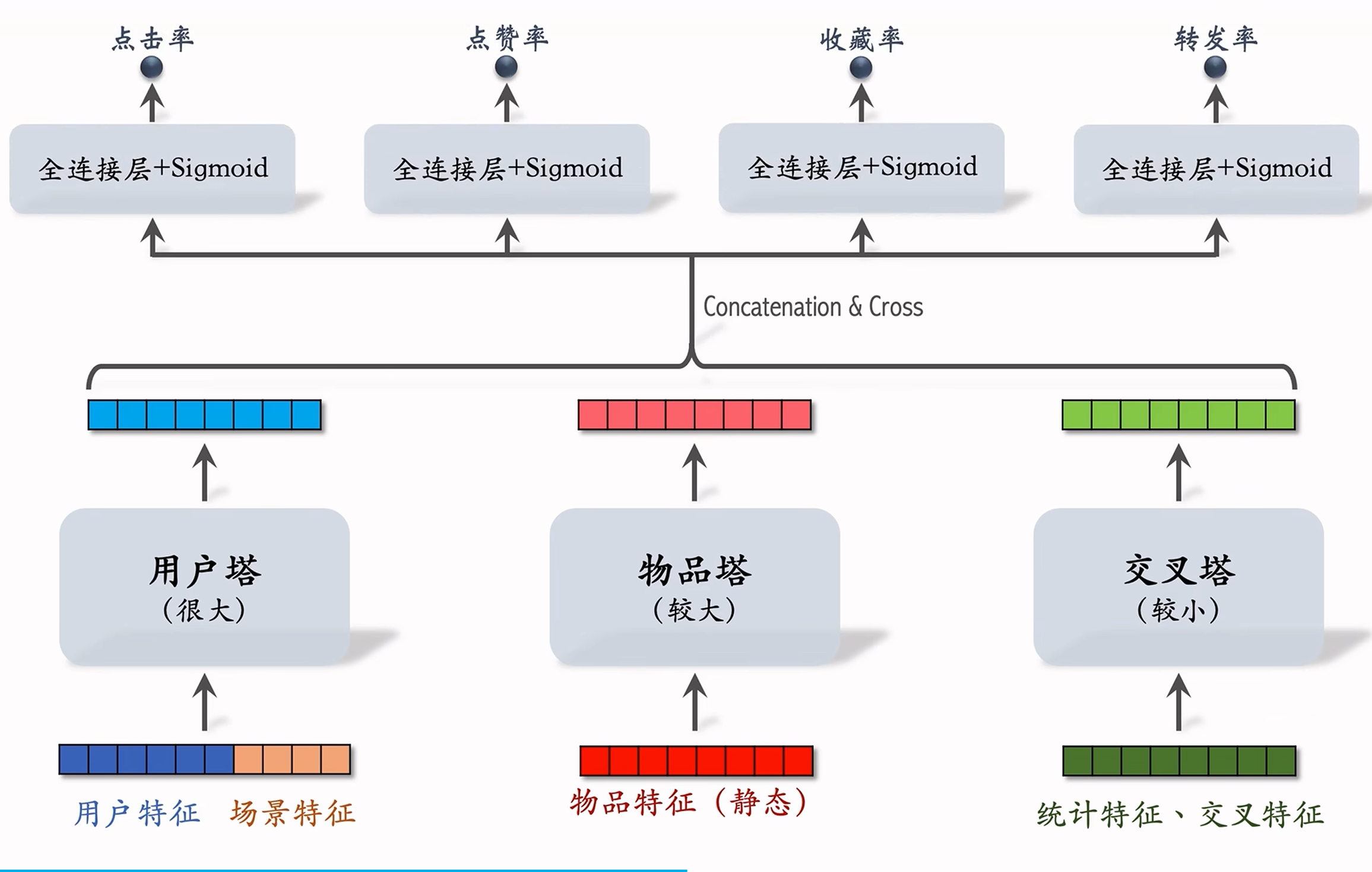 如图可见,实际上粗排模型的输出、训练与精排完全一致,主要区别在于下面的三个塔,该模型介于前期融合和后期融合之间,特征向量在经过神经网络之前不做融合,之后做融合,并且每个塔的参数量不一样,这样设计的原因在于:
如图可见,实际上粗排模型的输出、训练与精排完全一致,主要区别在于下面的三个塔,该模型介于前期融合和后期融合之间,特征向量在经过神经网络之前不做融合,之后做融合,并且每个塔的参数量不一样,这样设计的原因在于:
- 只有一个用户,用户塔只用做一次推理。因此即使用户塔很大,总计算量也不大。
- 有
个物品,理论上物品塔需要做 次推理。所以需要缓存物品塔的输出向量(物品特征相对稳定,短期内不会发生变化),避免绝大部分推理(只有遇到新物品才需要做推理)。 - 交叉塔输入的统计特征等会动态变化,缓存不可行。而有
个物品,交叉塔必须要做 次推理,所以交叉塔必须要小,计算够快。
而在模型的上层,有 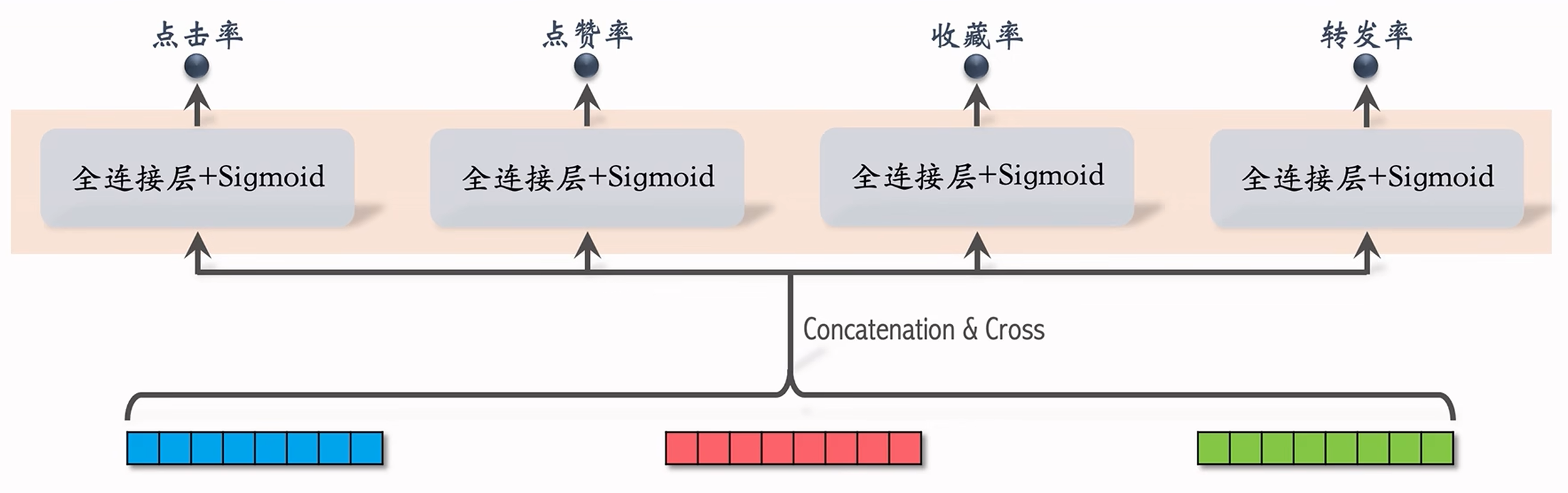 总结三塔模型的推理:
总结三塔模型的推理:
- 从多个数据源取特征:
(1) 1 个用户的画像、统计特征;
(2)个物品的画像、统计特征。 - 用户塔:只做一次推理。
- 物品塔:未命中缓存时需要做推理。
- 交叉塔:必须做
次推理。
5.上层网络做次推理,给 个物品打分。
本章小结
本章主要讲解了排序中的粗排模型与精排模型。
精排模型为多目标模型,先融合用户和物品的多个特征输入神经网络(shared bottom),输出各个指标的预估值(前期融合)。
在多目标模型的基础上,前人提出了MMoE模型。它的基本思想是对于不同的目标,先利用“专家”得到多个表征向量,同时分别利用神经网络得到不同的权重,最后对向量做加权平均输出预估值。该模型因为使用 Softmax 函数,会不可避免的出现极化现象,通过使用 Dropout 可以强迫每个 expert 都参与训练决策。
而小红书的粗排模型是三塔模型。它与精排模型的不同在于下层结构是先通过塔(神经网络)得到特征向量。再融合向量输出预估值,是介于前期融合和后期融合(双塔模型)之间的一种思想。这种思想有利于粗排快速推理,降低线上计算代价。
虽然以上模型架构有所区别,但是它们同归排序模型,具有相同的训练方式。在训练之前,与召回相似,需要收集用户与物品的多维特征并进行特征处理(embedding、异常值、缺失值等)。在模型训练时,将问题转化为二分类问题,使用交叉熵损失训练。训练的时候存在类别不平衡问题,需要进行负样本降采样。而且,在模型训练后,需要做预估值校准,才能进行排序。训练完模型进行线上排序时,需要融合模型输出的多个指标预估值再排序,而针对不同的任务有不同的融分公式。
除此之外,另外单独介绍了对视频播放的建模方法。对视频播放建模还需要单独考虑播放时长和完播率,并给出了对应的预估值和训练、推理方式。
下一章是对特征交叉方法的介绍,该方法常用于召回和排序之中。