四、特征交叉
✨文章摘要(AI生成)
概述推荐特征交叉方法,涵盖FM、DCN、LHUC与FiBiNet。
特征交叉是对多个单独特征进行组合(内积、外积、笛卡尔积等)来合成特征的过程,实现对样本空间的非线性变换,来<mark style="background: #BBFABBA6;">增加召回和排序模型的非线性能力</mark>。
Factorized Machine(FM)
Factorized Machine(FM)是早些年常用的特征交叉手段,现在已经不再使用 FM 做特征交叉了,可以通过FM的思想了解早些年特征交叉的做法。
线性模型
线性模型对输入的特征取加权和,作为对目标的预估,基本思想如下:
- 设有
个特征,记作 ; - 则线性模型公式为:
; - 线性模型有
个参数:权重 和偏置 ; - 显然,预测值
是特征的加权和(只有加,没有乘意味着特征之间没有交叉)。 如果做二分类,可以对 额外使用sigmoid
二阶特征交叉(POLY2)
如果先做特征交叉,再用线性模型,通常能取得更好的效果。二阶交叉特征基本思想如下:
- 设有
个特征,记作 ; - 二阶特征交叉:
; - 线性模型 + 二阶特征交叉:
; - 模型有
个参数(主要是二阶特征交叉中的权重 )。
特征交叉使得线性模型中的特征不仅仅只是相加,还能相乘,有效提升了模型的表达能力。
Factorized Machine(FM)
在实际做二阶特征交叉时,上述的二阶特征交叉参数量为特征数量的平方级,因为参数量大导致的计算量大,并且容易造成过拟合。因此,提出FM方法降低参数量和计算量,其基本思想如下:
- 对于二阶交叉特征中的权重系数
,通常组成权重矩阵 来方便计算; - 由于矩阵
是 维的,可以进行低秩矩阵分解,得到 维的矩阵 满足 ; - 所以对应的权重系数满足
,替换线性模型 + 二阶特征交叉的组合,得到 Factorized Machine 的公式: ; - FM 模型有
个参数,这里的 。
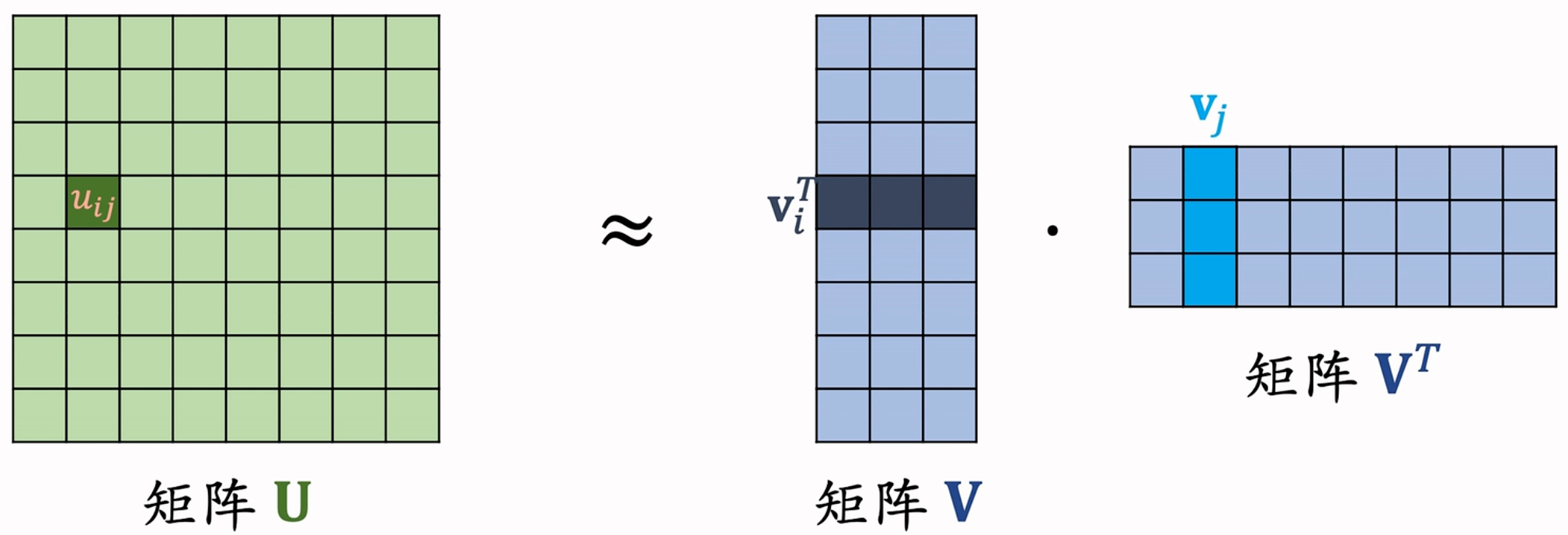
因此,总结下FM 的主要优点在于:
- FM 是线性模型的替代品,能用线性回归、逻辑回归的场景都可以用 FM ;
- FM 使用二阶交叉特征,表达能力比线性模型更强;
- 通过做近似
,FM 把二阶交叉的权重数量从 降到了 ,大大地加速了计算。
DCN 深度交叉网络
前序介绍地召回双塔模型、粗排三塔模型以及精排模型,它们应用的神经网络默认为简单的全连接网络,但也可以替换成本节将要介绍的深度交叉网络或者任何更好的网络架构,取得更好的召回或排序效果。总之,<mark style="background: #BBFABBA6;">DCN可以应用于召回或排序模型</mark>
- 双塔模型中的塔
- 精排过程中多目标模型里的shared bottom
- MMoE中的专家网络
深度交叉网络(Deep & Cross Networks,DCN)由一个深度网络和一个交叉网络组成,交叉网络的基本组成单元是交叉层 (Cross Layer)。
交叉层
如下图所示,是交叉层的基本结构: 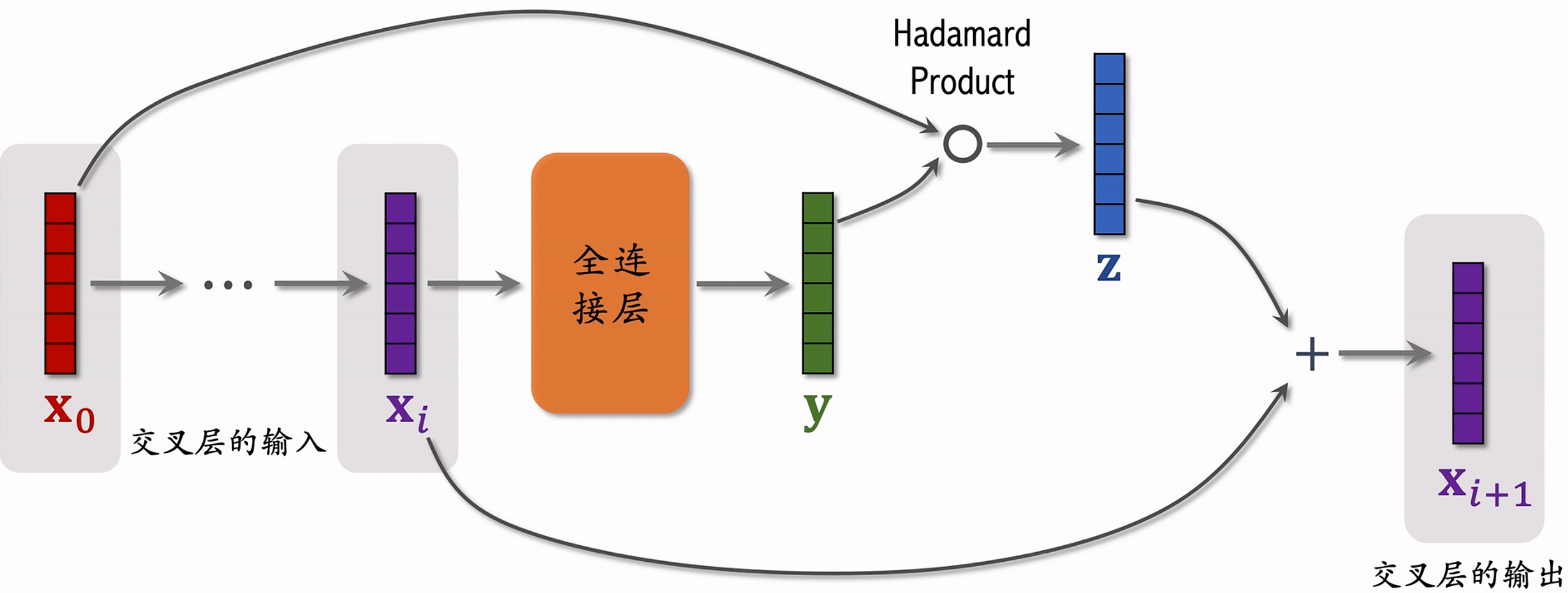 其流程为:
其流程为:
- 初始输入向量
,经过若干层神经网络后输出向量 ,这两个都是交叉层的输入; - 将向量
输入全连接层,输出向量 ; - 初始输入
和向量 的Hadamard 乘积(对应位置逐个元素相乘)得到向量 ; - 将向量
和 加和得到交叉层的输出 ,该操作即ResNet中的跳跃连接,是深度学习中的常用技巧,可防止梯度消失。
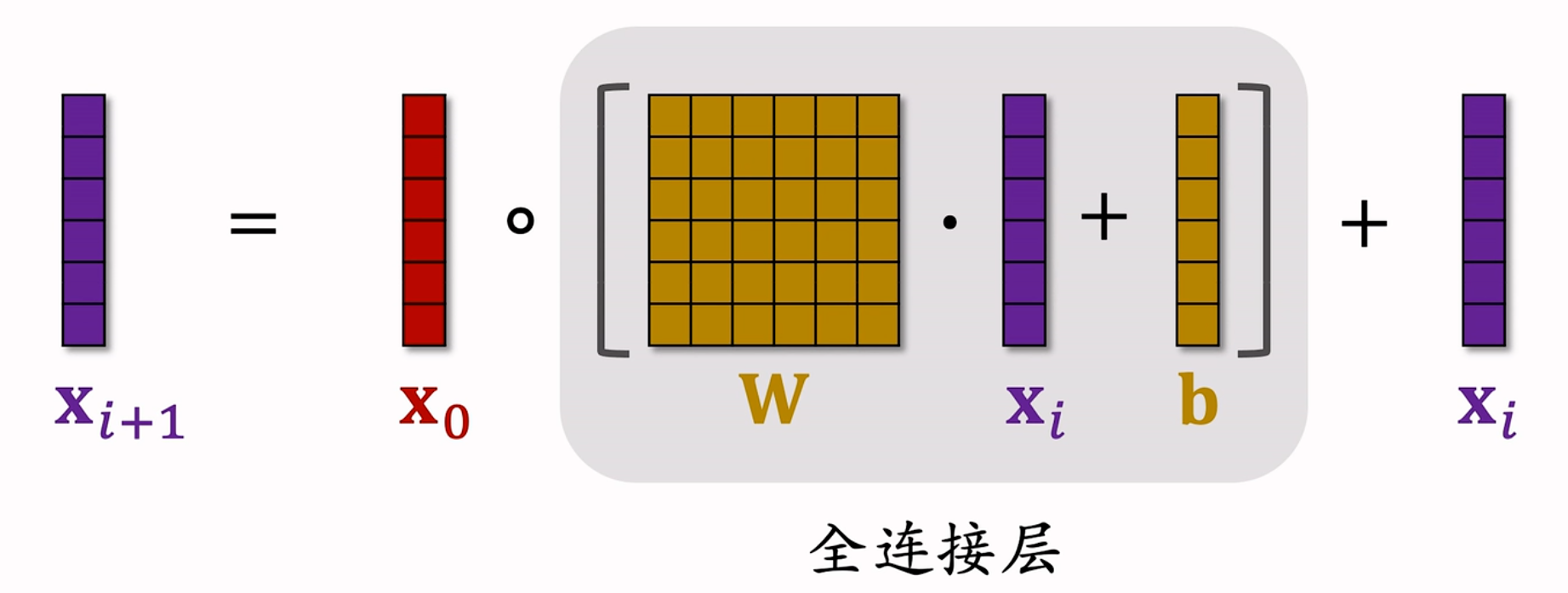 所以,交叉层的主要参数在所使用的全连接层中(训练过程中需要根据梯度更新),其他的求和与求 Hadamard 乘积的操作不涉及参数。故交叉层也可以写成公式:
所以,交叉层的主要参数在所使用的全连接层中(训练过程中需要根据梯度更新),其他的求和与求 Hadamard 乘积的操作不涉及参数。故交叉层也可以写成公式:
其中
每个交叉层的输入、输出都是形状相同的向量
交叉网络
如下图所示, 是Cross Network V2的基本架构: 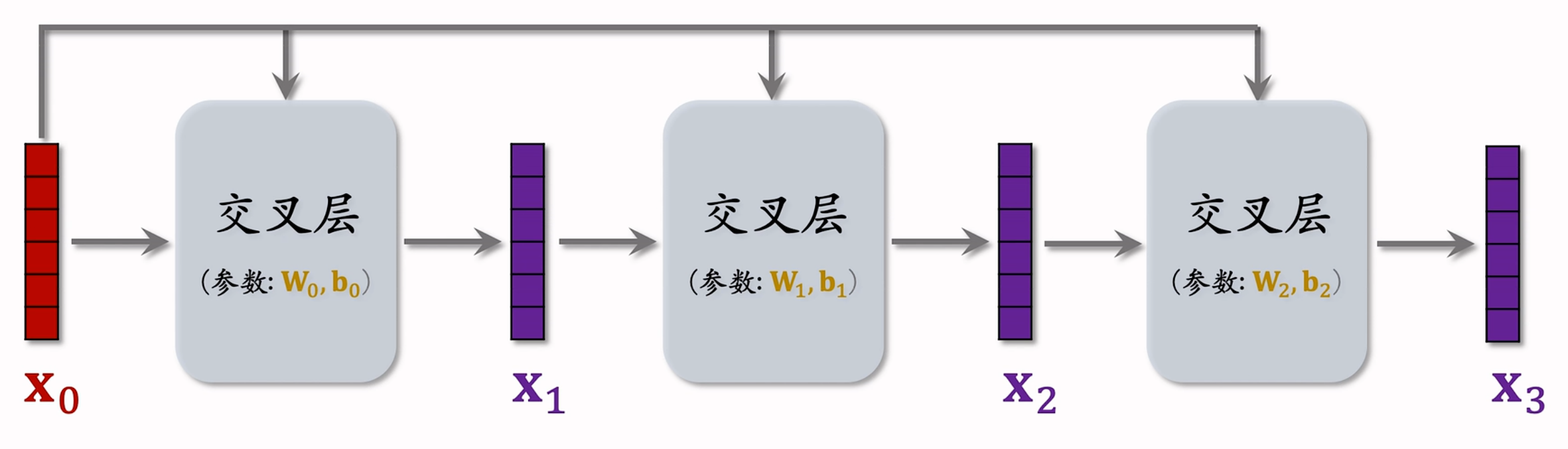 其中值得注意的是,第一个交叉层的输入只有一个初始向量
其中值得注意的是,第一个交叉层的输入只有一个初始向量
深度交叉网络
如下图所示,深度交叉网络的基本思想就是将用户和物品的特征拼接起来,分别输入全连接网络和交叉网络,将得到的两个向量拼接后输入全连接层,得到最后的输出。 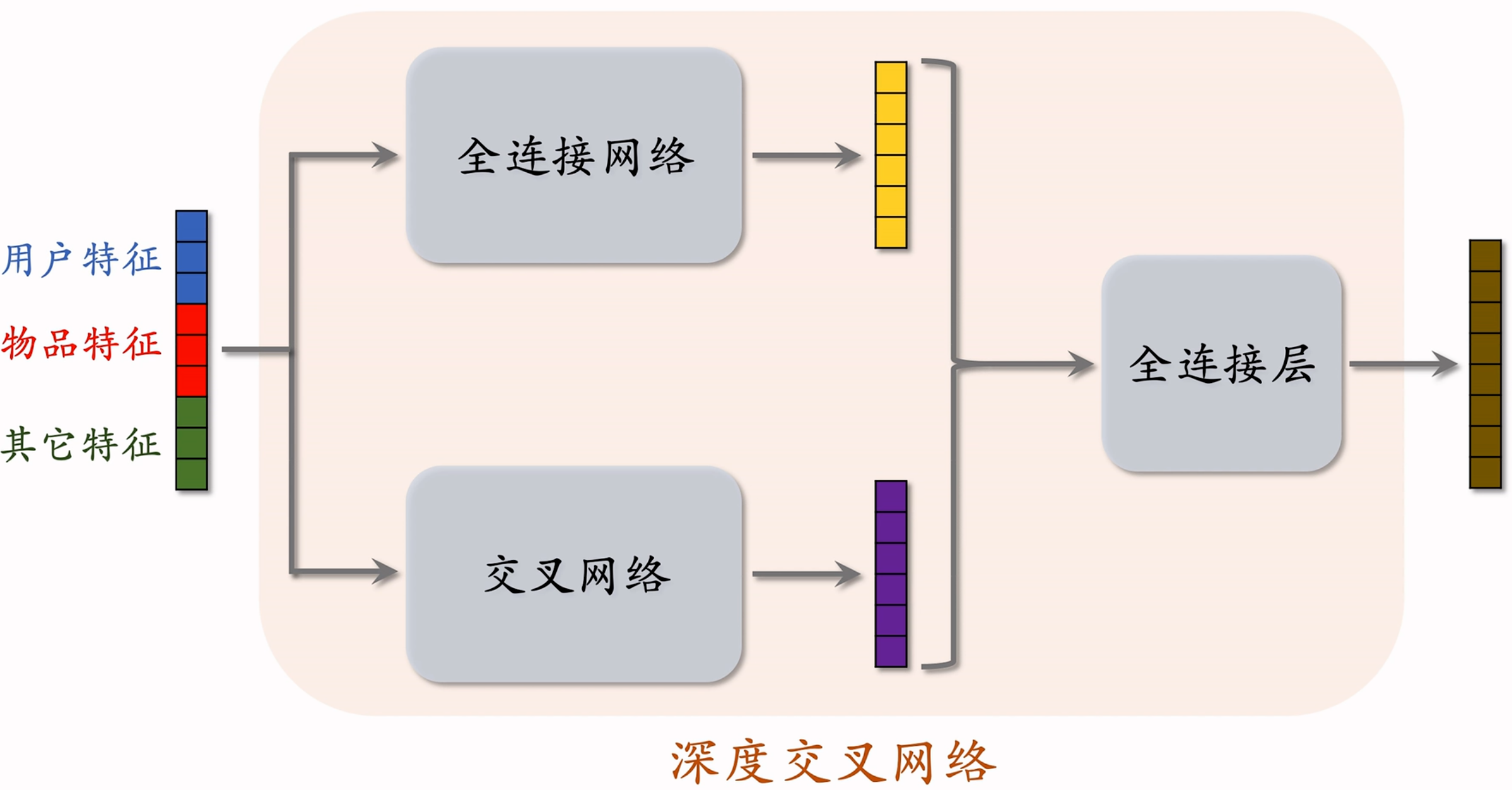
LHUC(PPNet)
LHUC(Learing Hidden Unit Contributions)也是一种神经网络结构,与 DCN 的思想有些类似,可以用于<mark style="background: #BBFABBA6;">精排</mark>。LHUC 的起源是语音识别,后来被应用到推荐系统,快手将其称为 PPNet,现在已经在业界广泛落地。
语音识别中的LHUC
语音识别的输入是一段语言信号,目标是对该信号做变换得到表征,可以实现识别出其中文字。而不同的人的语速、腔调都不同,所以需要加入一些个性化因素,需要将说话者的特征也作为输入。如下图所示是语音识别中的 LHUC 架构: 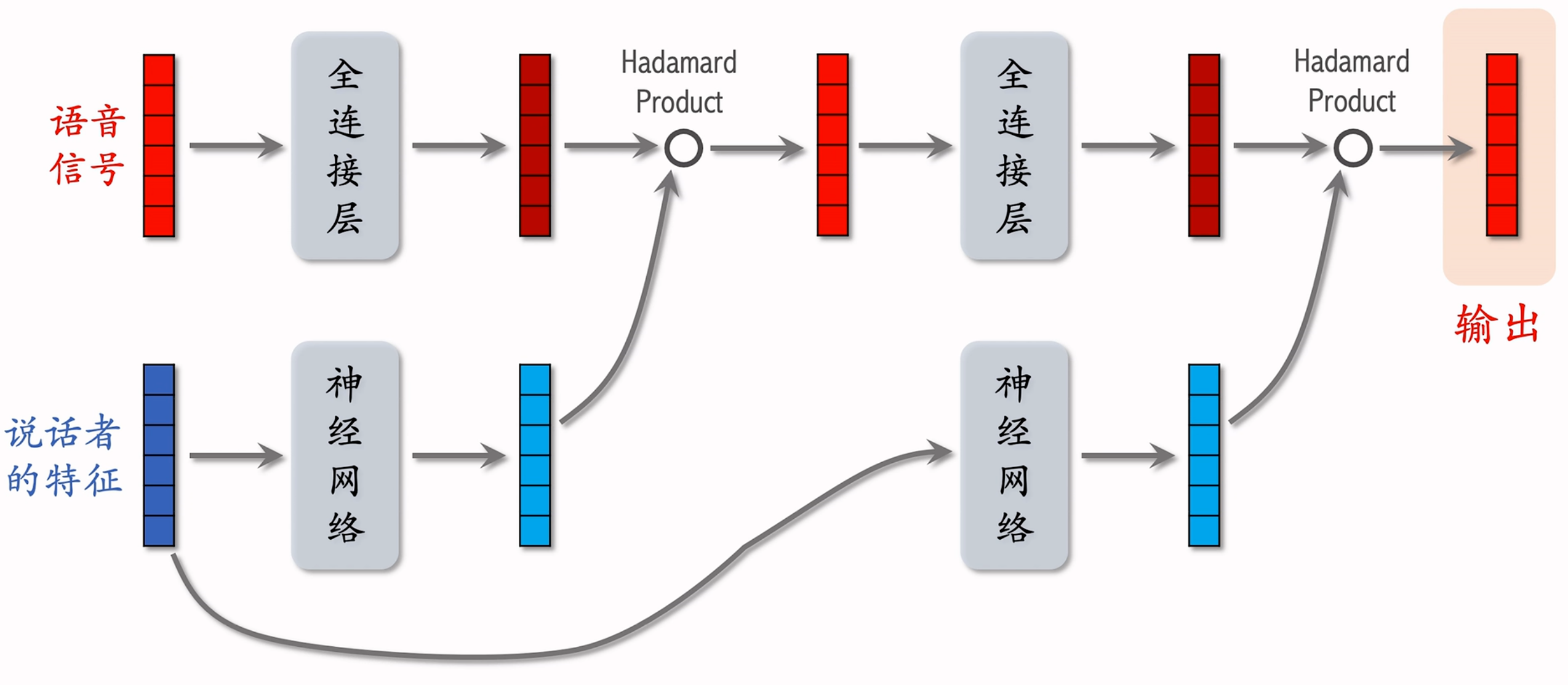 其中值得注意的是:
其中值得注意的是:
- 图中两个“神经网络”的输入都是初始输入中说话者的特征,与上面全连接层不同;
- 图中“神经网络”的结构为多个全连接层+Sigmoid变换后乘以2,这样与语音信号做 Hadamard 乘积时,可以放大或缩小一些特征,实现个性化;
- 如果需要更深层的网络,可以继续如上图操作叠加。
精排模型中的LHUC
快手将LHUC用于精排模型,称作PPNet,该精排模型中,将LHUC的中“语音信号”替换为“物品特征”,“说话者的特征”替换为“用户特征”,其他结构不变。 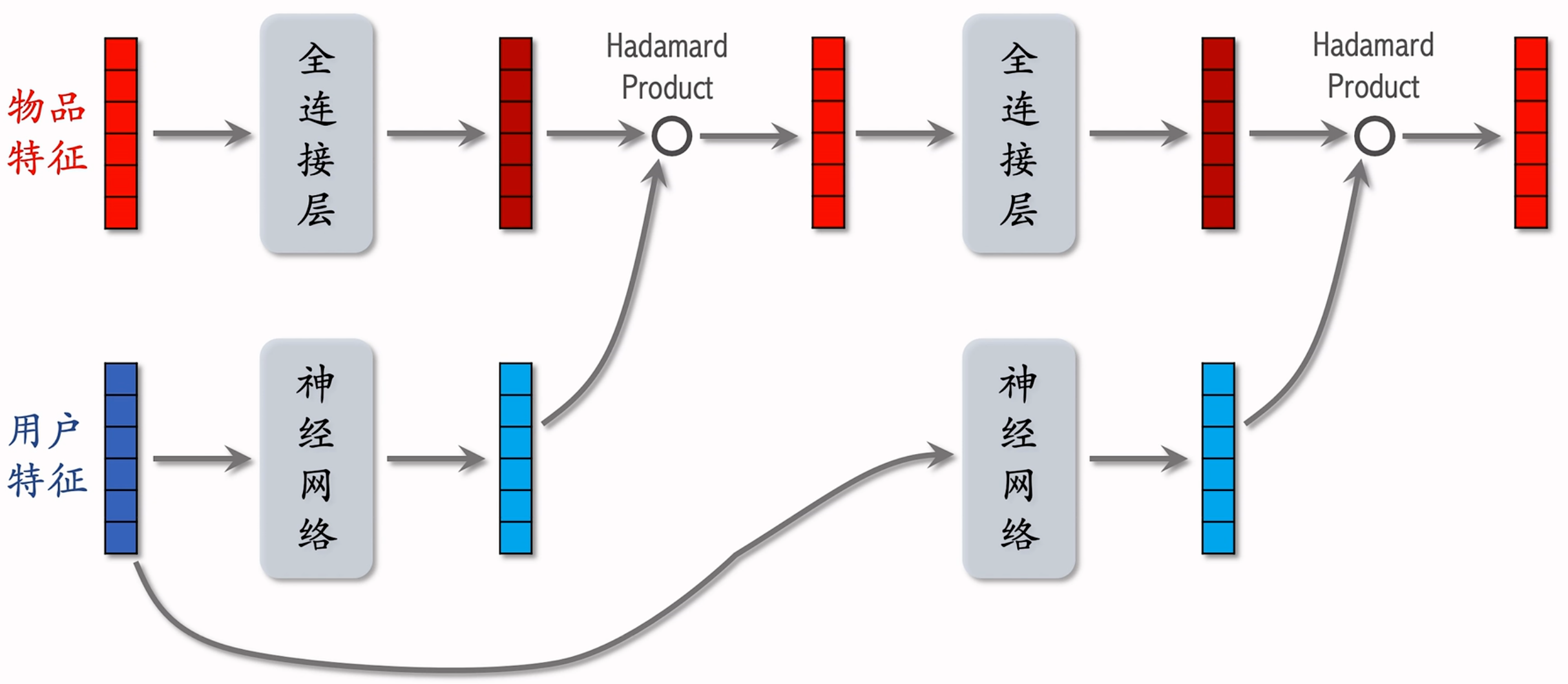
FiBiNet
SENet 和 Bilinear 交叉一般应用在<mark style="background: #BBFABBA6;">排序</mark>模型中,都有一定的正收益。
SENet
SENet 是计算机视觉中的一种技术,可以用在推荐系统中对特征做动态加权。在推荐系统中的 SENet 架构如下: 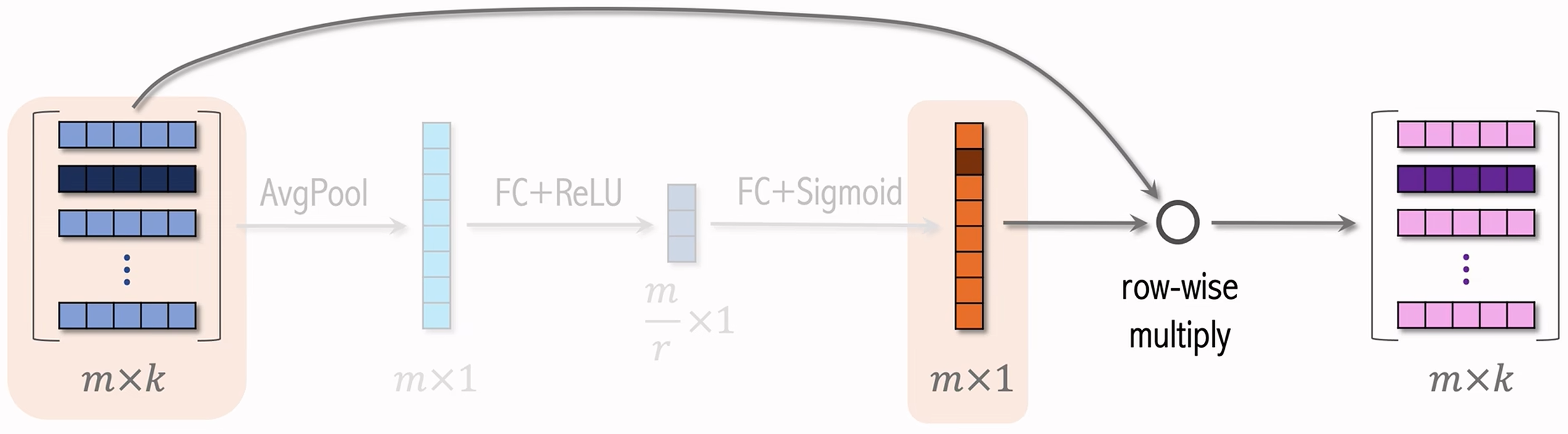 图中输入
图中输入 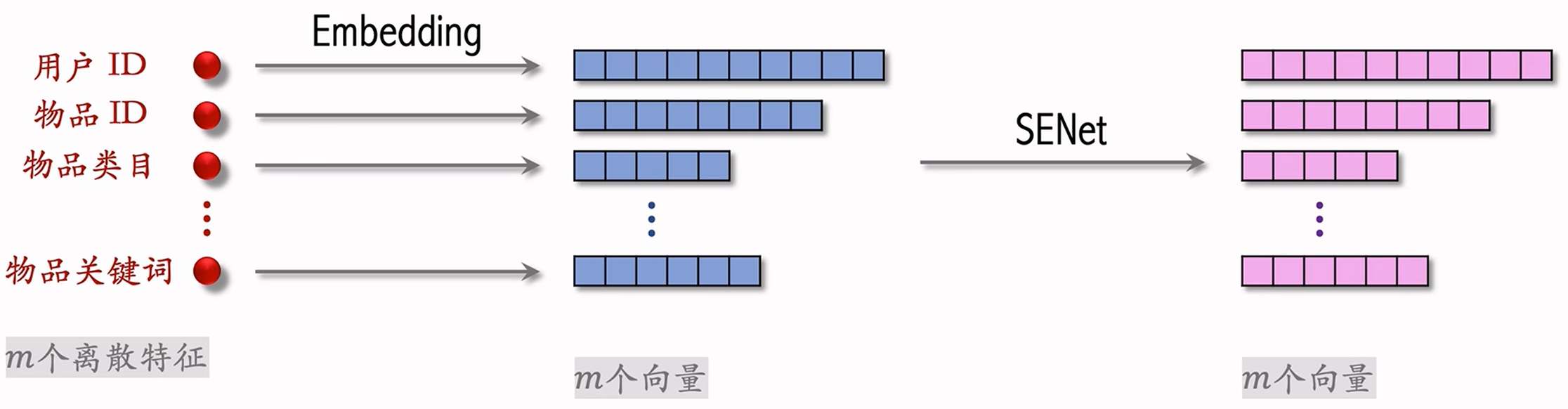 SENet的基本思想为:
SENet的基本思想为:
- SENet 对离散特征做 field-wise 加权,即SENet根据所有特征自动判断每个field重要程度;
- 如上图所示,field 如下解释:若某特征的 embedding 是
维向量,称向量中的 个元素归为一个field,获得相同的权重; - 如果有
个 field ,那么权重向量是 维的; - 值得注意的是,不同的特征 embedding 向量维度可以不同。
Bilinear Cross
与SENet针对特征做field-wise加权不同,下面重点关注Field之间的特征交叉,通过将两个Field做交叉得到新的特征,例如把物品所在地和用户所在地的embedding做交叉。
前面使用过的内积和 Hadamard 乘积都是在 field 间做简单特征交叉方法,不妨设有两个同为
- 内积:
; - Hadamard 乘积:
。
如果有 个filed,那么求内积得到
- 基于内积的 Bilinear Cross:
,其中 为 维的参数矩阵 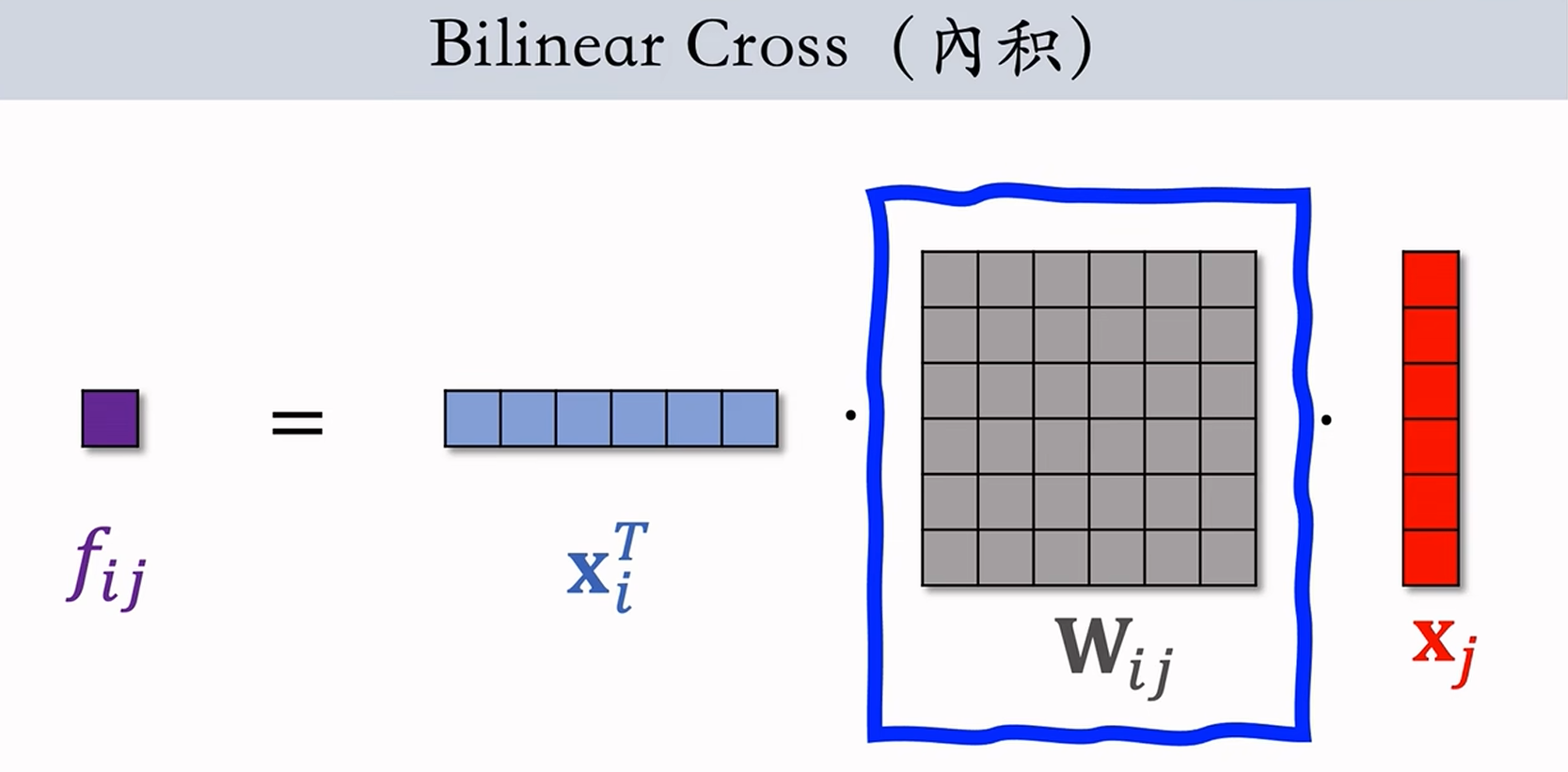
- 基于 Hadamard 乘积的Bilinear Cross:
,其中的 为 维的参数矩阵,区别在于把第一个内积换成 Hadamard 乘积同时不需要对 做转置 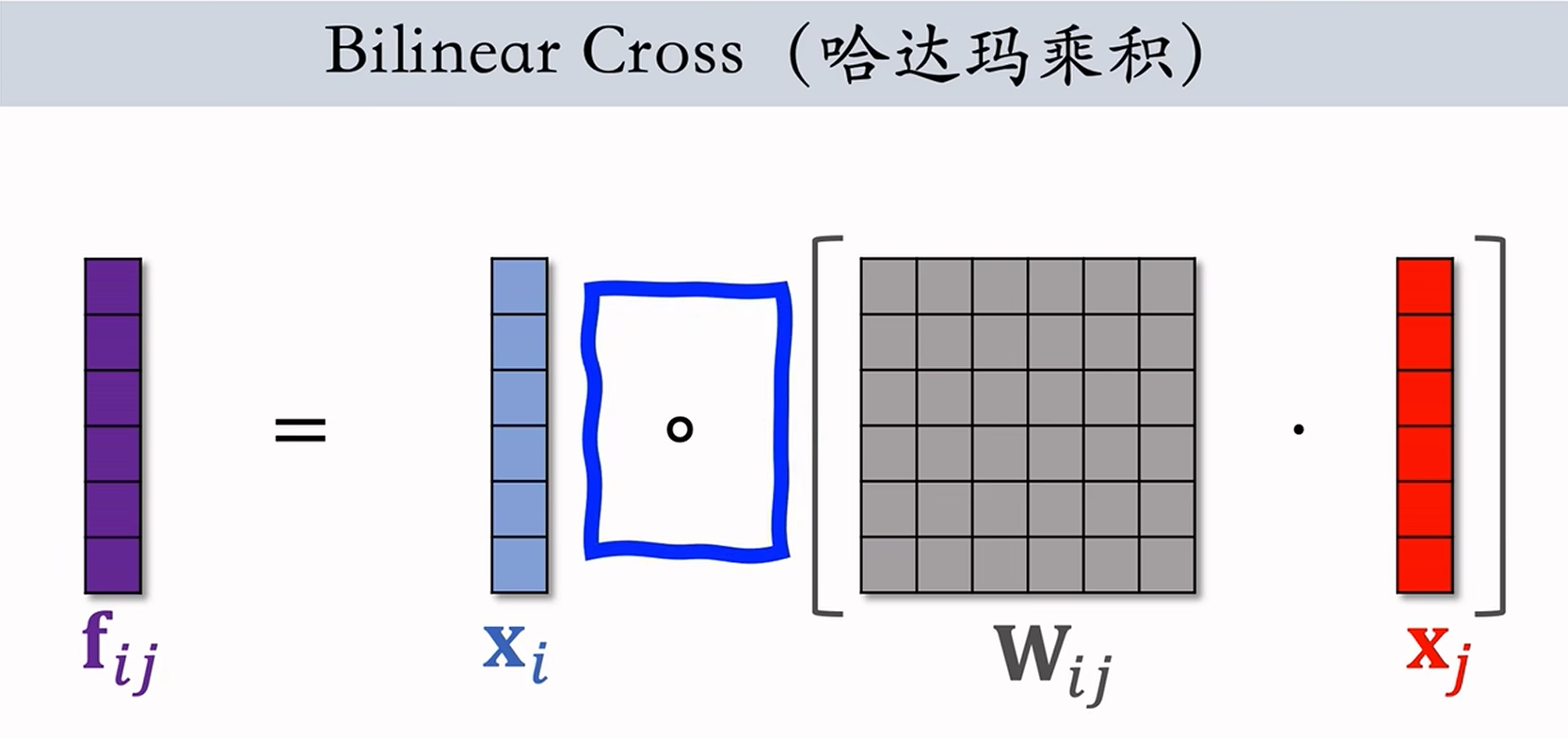 同样如果有
同样如果有 个filed,那么基于内积的交叉方法会产生 个实数,但需要额外保存 个参数矩阵,数据量过大,要做人工的特征选择或者矩阵分解;第二种交叉方法得到 个向量,同样要做人工筛选。
FiBiNet
FiBiNet 是 SENet 与 Bilinear Cross 的结合,模型架构如下: 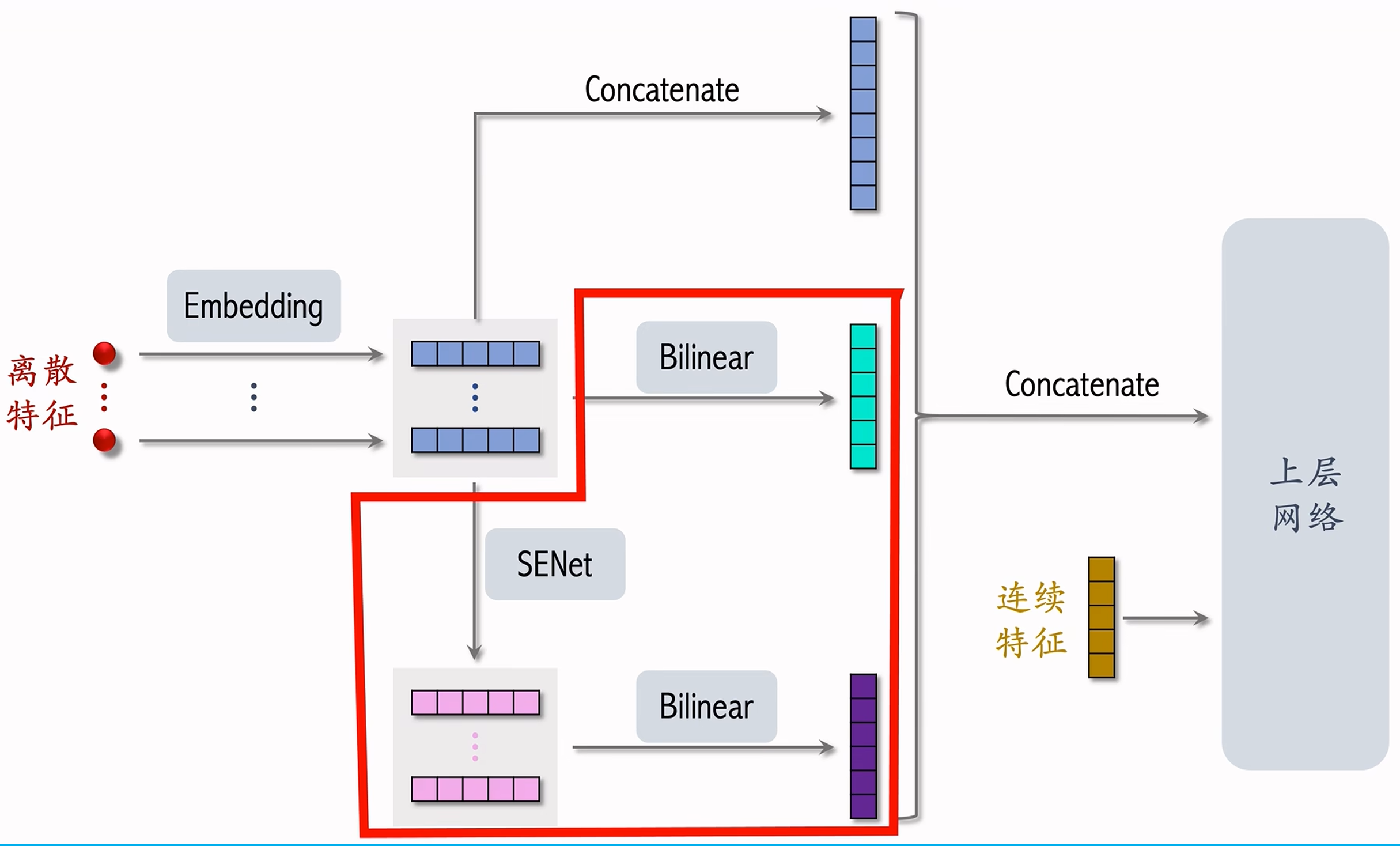 该模型与排序模型的区别主要在离散特征的处理上,引入了 Bilinear Cross 做特征交叉和使用 SENet 进行特征embedding 的动态加权。在小红书的实际应用中,并没有招搬该模型,比如其中在 SENet 之后的 Bilinear Cross 被认为是无意义的。
该模型与排序模型的区别主要在离散特征的处理上,引入了 Bilinear Cross 做特征交叉和使用 SENet 进行特征embedding 的动态加权。在小红书的实际应用中,并没有招搬该模型,比如其中在 SENet 之后的 Bilinear Cross 被认为是无意义的。
本章小结
特征交叉有利于捕获特征间的共现关系,从而提升模型准确度。同时,通过特征交叉可以生成新的特征,甚至未知的特征组合,有利于提升模型泛化能力。最后,现实世界是高度非线性的,通过内积、外积、Hadamard 积、Bilinear Cross 等特征交叉方式,可以提升模型非线性能力。
早些年常用的 Factorized Machine(FM)是基于线性模型和二阶特征交叉组合的,FM 使用低秩矩阵分解,将二阶特征交叉中的权重矩阵近似分解为两个低秩矩阵,以减少计算量,防止过拟合。不过业界早已不再使用 FM。
随后介绍了两种可用于替换召回或排序模型中神经网络的模型架构,它们都是基于 Hadamard 积和特征交叉进行改进的。第一个是深度交叉网络(DCN),可被用于召回和排序中。它由一个深度网络和一个交叉网络组成,交叉网络的基本组成单元是交叉层,交叉层即是对输入特征的一种特征交叉。DCN 的基本思想就是将用户和物品的特征拼接起来,分别输入全连接网络和交叉网络,将得到的两个向量拼接后输入全连接层得到最后的输出。
第二个是 Learing Hidden Unit Contributions (LHUC),它是被用于精排中的一种神经网络结构。LHUC 源于语言识别,而它在推荐系统中利用物品特征和用户特征做特征交叉,思想与 DCN 相似。其中对于用户特征的输入使用多层全连接层+Sigmoid乘以2以实现调整物品特征表征的权重,以实现个性化。
最后,本章还介绍了一种由SENet 和 Bilinear Cross 组合的模型 FiBiNet ,常用于排序中。该模型与排序模型的区别主要在离散特征的处理上,引入了 Bilinear Cross 做特征交叉和使用 SENet 进行特征embedding 的动态加权。在小红书的实际应用中,对 FiBiNet诸多地方有所调整优化。