六、重排
✨文章摘要(AI生成)
梳理推荐重排中的多样性方法:基于相似度的 MMR、基于行列式的 DPP,以及滑动窗口与业务规则约束的工程落地。
重排是对精排结果的顺序进行再次微调,一方面是为了实现全局视角的最优排序,另一方面是为了满足特定业务诉求和提升用户体验。实际上重排是对推荐系统中多样性的考察,多样性更能体现用户的个性化。如果多样性做得好,可以显著提升推荐系统的核心业务指标。
推荐系统中的多样性
这节是对多样性相关基础知识的介绍。在介绍多样性算法前,先了解对物品相似度的度量方法和提升多样性的方法。
物品相似度的度量
度量两个物品相似度的方法主要有两种。第一种是基于物品属性标签的方法:
- 物品属性标签:类目、品牌、关键词等;
- 譬如,可以根据一级类目、二级类目、品牌计算相似度:
(1)物品:美妆、彩妆、香奈儿;物品 :美妆、香水、香奈儿;
(2)相似度:对以上三个相似度求加权和得到物品相似度,权重由人为设定。
第二种是基于物品向量表征的方法。前文介绍过,在召回的双塔模型中,物品塔学习物品的向量计算相似度,但是由于长尾数据的问题,这种方法实际效果并不好,尤其不能处理好新物品和长尾物品。一般来说,更多的应用基于内容的向量表征,在小红书中就是用 CV 和 NLP 模型提取图片和文字特征向量。简单介绍如下:
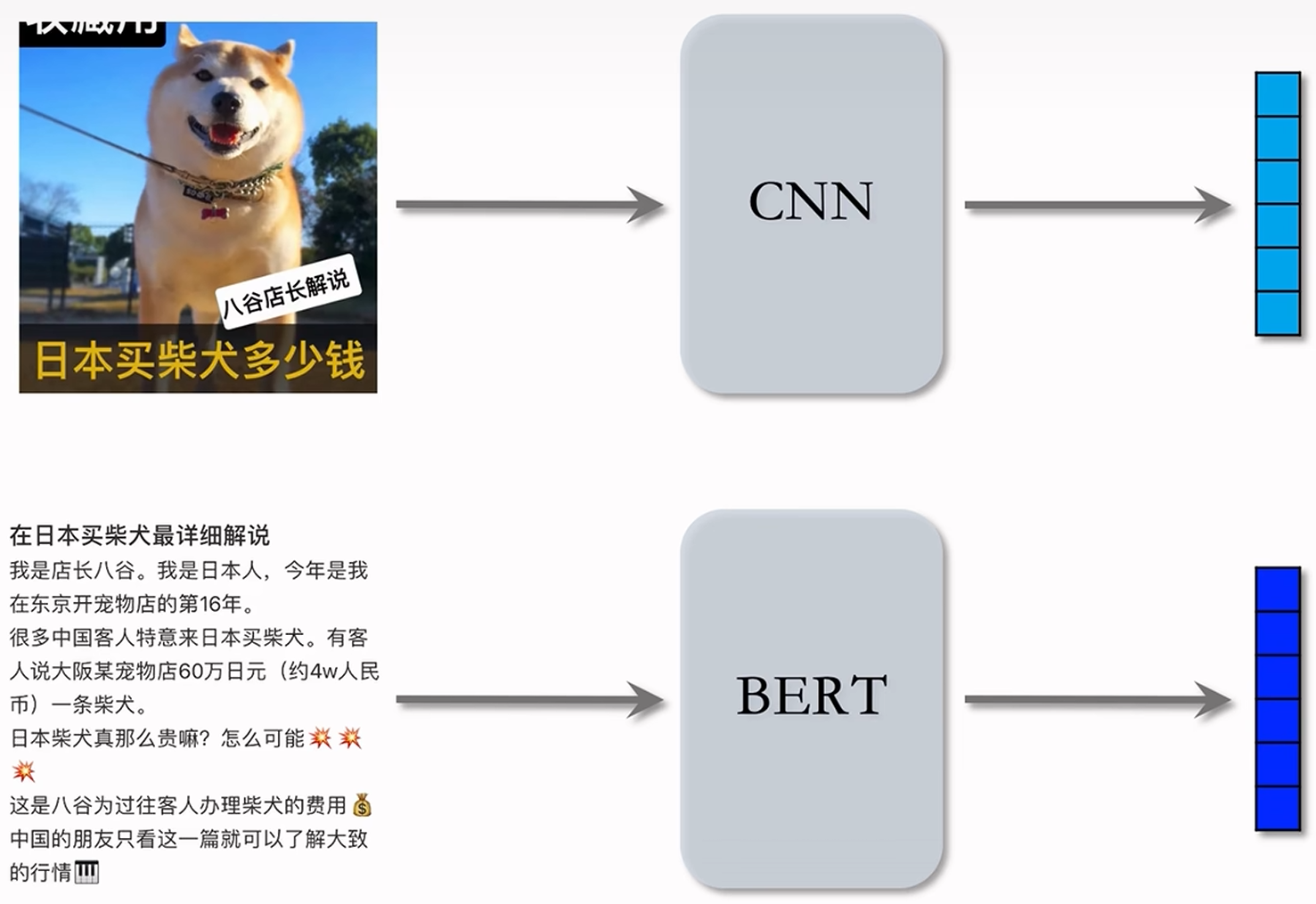
- 小红书的笔记大多是文字+图片的组合,一般来说图和文字相关性较大;
- 以只有一张图的情况为例,通过 CNN 模型将图片转化为向量,通过 BERT 模型将文字转化为向量;
- 将这两个向量拼接起来就是该图文笔记的向量表征,可以输入后续的任务中。
但是,这里存在一个问题,CNN 和 BERT 两个模型如何训练得到?如果使用数据进行训练,得到的模型并不适用于小红书的任务场景;如果人工标注数据,任务量非常大。所以,CLIP 是当前公认最有效的预训练方法,它的基本思想为:
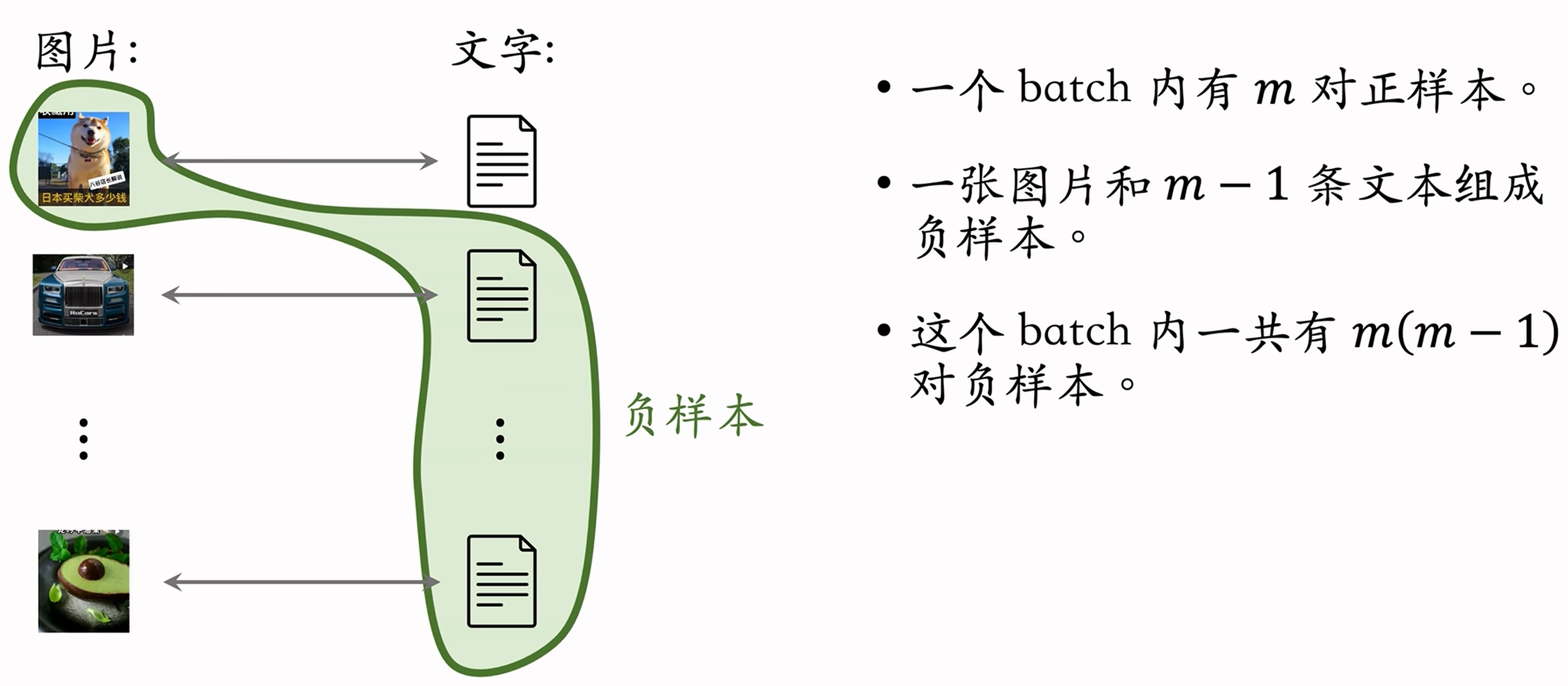
- 思想:对于“图片—文本”二元组,预测图文是否匹配。
- 正负样本:来自同一篇笔记的图文作为正样本,来自不同笔记的图文作为负样本(batch内负样本).
- 优势:无需人工标注。小红书的笔记天然包含图片和文字,大部分笔记图文相关。
提升多样性的方法
推荐系统中希望提高曝光物品多样性,也就是尽量使得物品之间两两不相似。前面主要介绍了粗排和精排的流程思想,但实际在粗排后精排之后需要进行后处理:
1. 粗排和精排用多目标模型对物品做 pointwise 打分。对于物品
,模型输出点击率、交互率等的预估,融合成分数 。 表示用户对物品的兴趣,即物品本身的价值。那么给定 个候选物品,排序模型打分为 。
2. 后处理则从个候选物品中选出 个,既要它们的总分高,也需要它们有多样性。
后处理的作用就是提升了多样性,有利于业务指标的增长。精排之后的后处理就是重排;而粗排之后一般也存在后处理,不可忽视。后面课程就是对工业界在后处理中多样性算法的介绍。 
MMR 多样性算法
Maximal Marginal Relevance(MMR)是最早来自于搜索排序的算法,使用相关性进行排序。要解决的问题设定如下:
- 精排给
个候选物品打分,融合之后的分数为 ; - 把第
和 个物品的相似度记作 ; - 根据以上两个值,从
个物品中选出 个作为曝光的结果,要求既要有高精排分数,也要有多样性。
MMR 多样性算法
不妨记选择的物品集合为 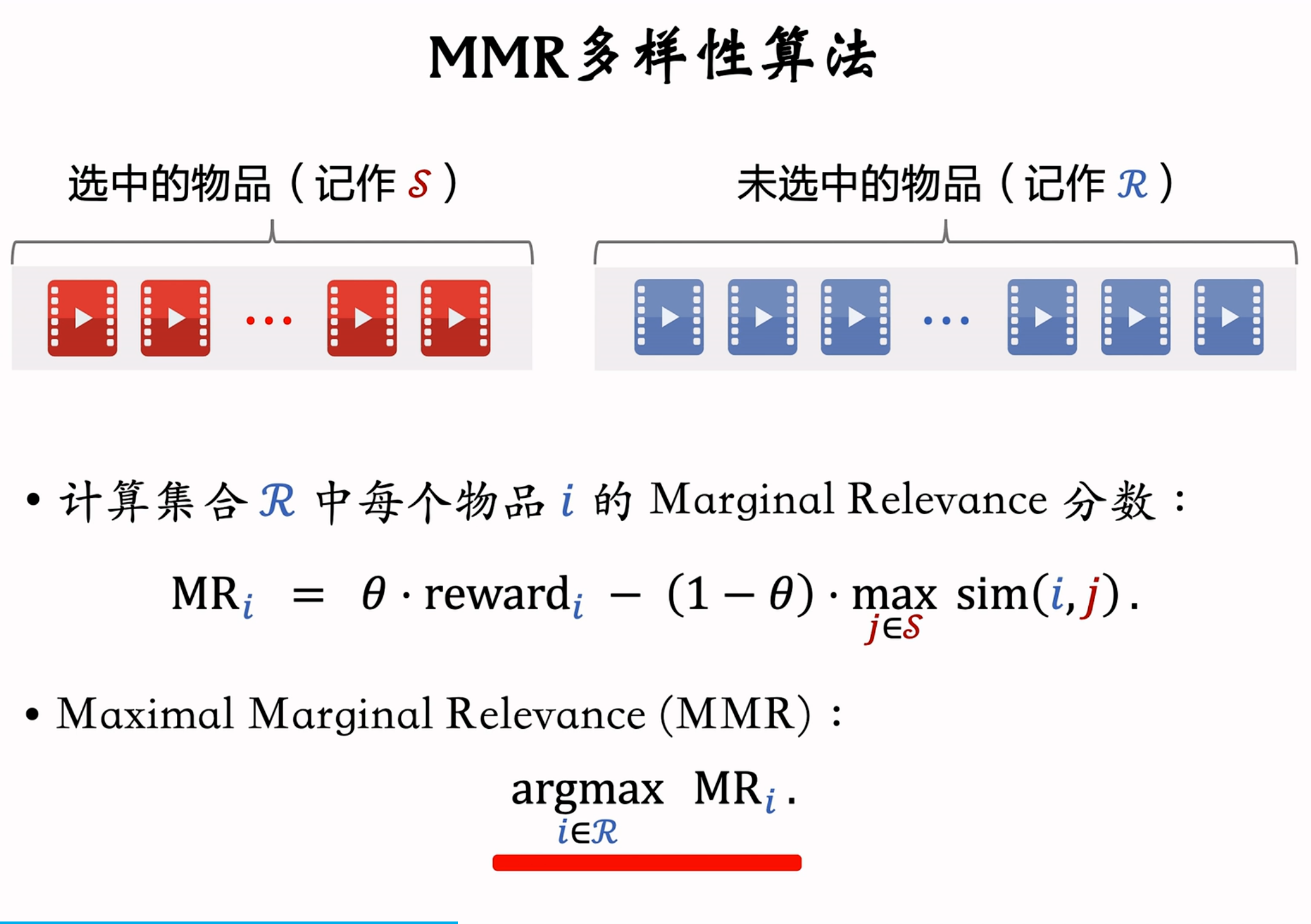 基于该分数,此则 MMR 的算法流程为:
基于该分数,此则 MMR 的算法流程为:
- 已选中的物品
初始化为空集,未选中的物品 初始化为全集 ; - 选择精排分数
最高的物品,然后从集合 移到 ; - 重复上一步做
轮循环:
(1)计算集合中中所有物品的分数 ;
(2)选出分数最高的物品,将其从移到 。
滑动窗口
在实际应用中,前面的公式
- 已选中的物品越多(即集合
越大时),越难找出物品 ,使得 与 中的物品都不相似; - 具体分析下原因:设
的取值范围为 。当 很大时,多样性分数 总是约等于 ,导致 MMR 算法失效。
针对这个问题提出的解决方案就是:设置一个滑动窗口 
业务规则约束下的多样性算法
工业应用为了保护用户体验,会设定很多业务规则。进行重排时必须要满足这些规则。
重排规则
规则的优先级要高于多样性算法,这里举出小红书中的几个典型例子:
| 规则 | 规则说明 |
|---|---|
| 最多连续出现 | 1. 小红书的推荐系统的物品分为图文笔记和视频笔记; 2. 最多连续出现 3. 如果排序 |
| 每 | 1. 运营推广笔记的精排分会乘以大于 1 的系数 (boost),帮助笔记获得更多的曝光; 2. 为了防止 boost 影响体验,限制每 3. 如果排第 |
| 前 | 1. 排名前 2. 小红书推荐系统带有电商卡片的笔记,过多可能会影响体验; 3. 前 |
MMR + 重排规则
将MMR 多样性算法与重排规则结合的方式:
- MMR每一轮选出一个物品:$$arg,max_{i\in R}{\theta\cdot reward_i-(1-\theta)\cdot\underset{j\in W}{max},,sim(i,j)}$$
- 重排结合 MMR 与规则,在满足规则的前提下最大化
:
(1)每一轮先用规则排除掉中的部分物品,得到子集 ;
(2)MMR 公式中的替换成子集 :$$arg,max_{i\in R'}{\theta\cdot reward_i-(1-\theta)\cdot\underset{j\in W}{max},,sim(i,j)}$$这样选中的物品符合规则。
DPP多样性算法
行列式点过程 (Determinantal Point Process, DPP) 是一种经典的机器学习方法,它的目标就是如何从一个集合中选出多样化的物品,与重排的目标契合。所以,DPP 是目前推荐系统重排多样性公认的最好方法。DPP 的数学比较复杂,需要先从其数学基础理论开始介绍。
DPP 数学基础
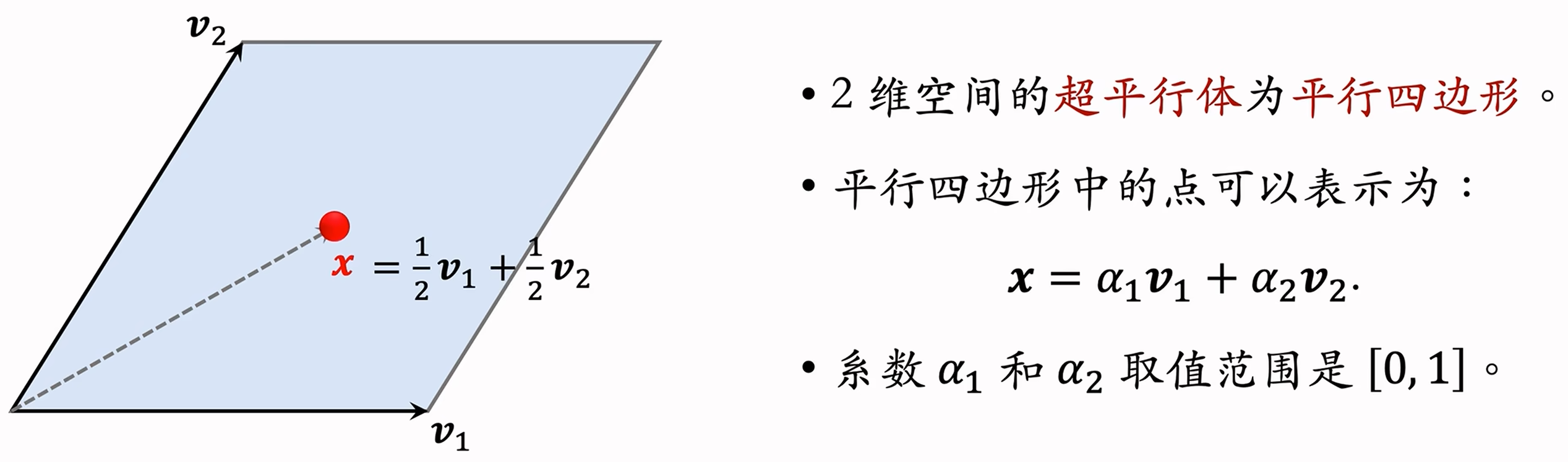
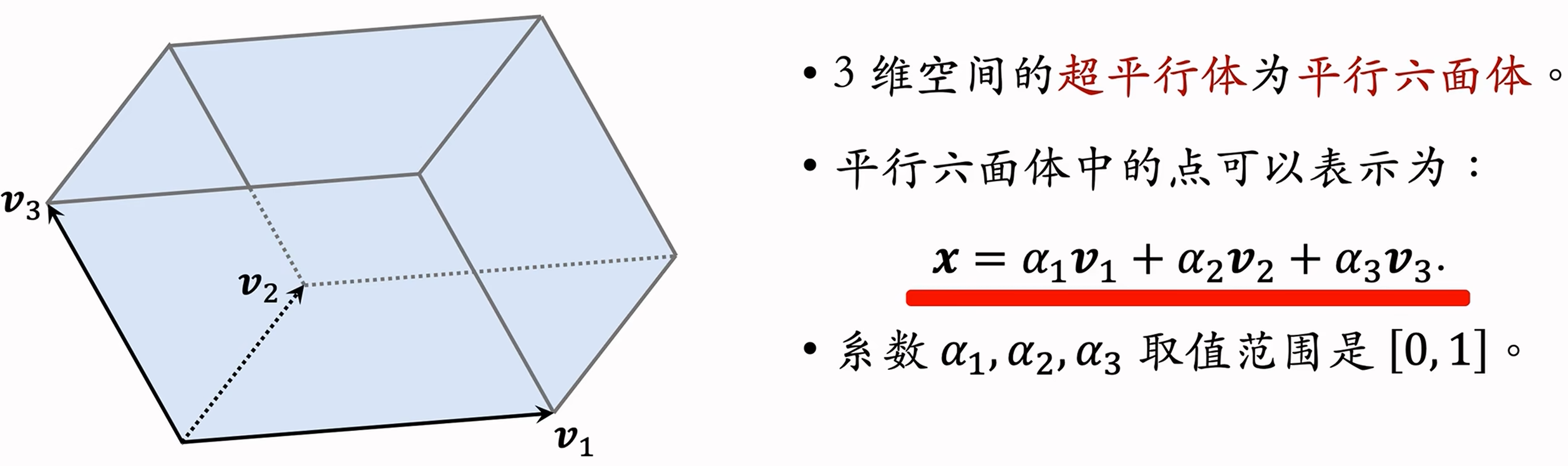
首先需要介绍下超平行体的概念。在二维和三维空间中,超平行体就是平行四边形和平行六面体。而在任意维上的定义为:
- 在
维空间中,一组向量 可以确定一个 维超平行体,这些向量是超平形体的边:$$P(v_1,...,v_k)={\alpha_1v_1+...+\alpha_kv_k,|,0\le\alpha_1,...,\alpha_k\le1}$$ - 这里要求
,例如 空间中有 维平行四边形。
 对于超平行体如何求面积(二维)和体积(三维),实际使用的是施密特正交化的思想,将不正交的向量组转化为正交的向量组,方便计算面积与体积。这里需要思考的是,如果都是单位向量时,什么条件下超平行体能取最大和最小的体积呢?显然如下结论:
对于超平行体如何求面积(二维)和体积(三维),实际使用的是施密特正交化的思想,将不正交的向量组转化为正交的向量组,方便计算面积与体积。这里需要思考的是,如果都是单位向量时,什么条件下超平行体能取最大和最小的体积呢?显然如下结论:
- 不妨设
、 、 都是单位向量; - 当三个向量正交时,平行六面体为正方体,体积最大化
; - 当三个向量线性相关时,体积最小化
。(三个向量都在一个平面上,显然体积为 0 。)
基于以上特点,我们可以如此利用体积来衡量物品多样性:
- 给定
个物品,将它们表征为单位向量: - 用超平行体的体积衡量物品的多样性,体积介于 0 和 1 之间;
- 如果
两两正交(多样性好),则体积最大化, ; - 如果
线性相关(多样性差),则体积最小化, ;
在实际应用中,则:
- 给定
个物品,将它们表征为单位向量: - 把它们作为矩阵
的列; - 设
,则行列式与体积满足: ; - 因此,可以用行列式
衡量向量 的多样性。

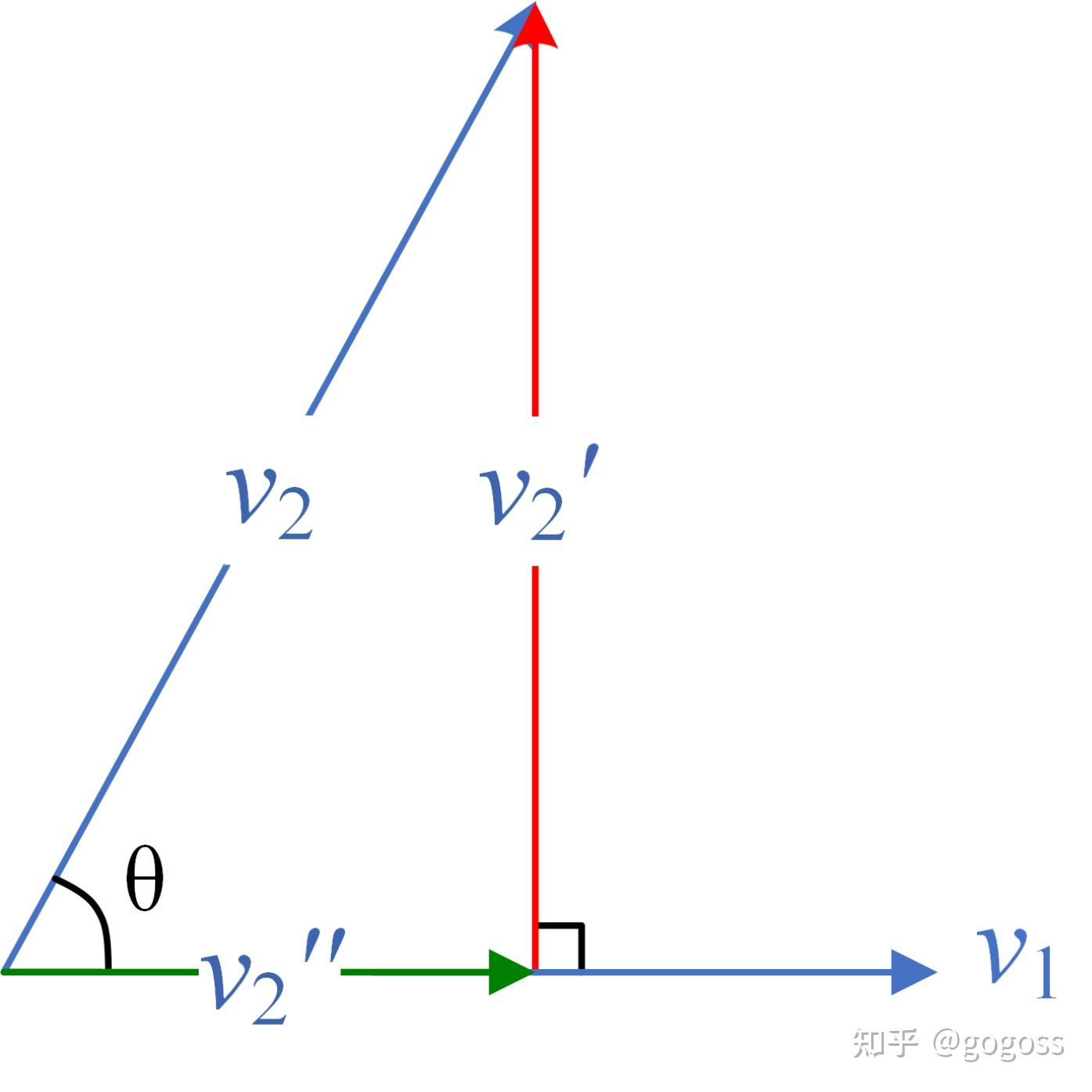
这里以二维超平行体为例,个人对行列式与体积的等式进行简单的验证推导:
不妨设向量
,其中 ,两向量夹角为 ,组合向量得到矩阵 和它的转置 ; 首先,如下图所示,对于二维向量组成的平行四边形,不妨以
为底,则面积由 和由 转化与底正交的向量 的模相乘得到,所以等式左边: 根据行列式的定义,有
整理后得:
根据向量夹角和余弦的定义:
,所以得到 代入上步式子中有:
显然该式与第 2 步中推理的等式左边相等,证毕。
DPP 多样性算法
前面对于超平行体的体积与多样性的关系进行了阐述,因此之前所介绍的多样性问题可以被描述为:
- 设有
个物品,向量表征为: ,精排给这些物品打分为: ; - 现在从
个物品中选出 个物品,组成集合 ,要求:
(1)价值大:分数之和越大越好;
(2)多样性好:中 个向量组成的超平行体 的体积越大越好。 - 将集合
中的 个物品向量组成矩阵 ,其中 。此时有 ,说明行列式等价于体积的平方,所以实际使用行列式衡量多样性。
DPP 求使得行列式的对数最大化的集合
设
为 的矩阵,它的 元素为 ;给定向量 ,则需要 时间计算 ; 那么
是 的一个 子矩阵,如果 时 是 的一个元素;替换后的 DPP 应用在推荐系统的公式写作: DPP 是个组合优化问题,从集合
中选出大小为 的子集 。用 表示已选中的物品,用 表示未选中的物品。因为DPP是个NP hard问题,不可能被精确求解,故使用贪心算法求解: 寻找一个物品
使得该物品价值尽量大、多样性尽量好。 其中
可以这样理解:寻找一个物品 ,给集合 添加一个新物品,所以在原本 的基础上添加了一行一列。同时,我们希望添加的物品 使得行/列式尽可能大,也就是说不能与集合 中的物品相似,否则行/列式接近于零。
现分析使用贪心算法暴力求解的时间复杂度:
- 求解:$$\underset{i \in R}{\operatorname{argmax}} \left{ \theta \cdot \operatorname{reward}i + (1-\theta) \cdot \log(\det(A{S \cup {i}})) \right}$$
- 对于单个
,计算 的行列式 (矩阵乘法) 需要 时间; - 那么对于所有的
,计算行列式需要 时间; - 然后需要求解上式
次才能选出 个物品,如果暴力计算行列式,则其总时间复杂度为:$$O(|S|^3 \cdot |R| \cdot k) = O(nk^4)$$ - 再考虑需要计算矩阵
需要 时间,所以暴力算法的总时间复杂度为:$$O(n^2 d + nk^4)$$ 可见,简单粗暴求解行列式花费了大量的代价,但系统留给多样性算法的时间非常有限(10毫秒左右)。因此 Hulu 的论文设计了一种快速数值算法,使用 **Cholesky 分解**花费 时间计算所有行列式,仅仅需要 的时间从 个物品中选出 个物品。该算法思想如下: - Cholesky 分解
,其中 是下三角矩阵,对角线以上的元素全为 ; - Cholesky 分解得到可供计算
的行列式: (1) 下三角矩阵 的行列式 等于 对角线元素乘积; (2) 故 的行列式为 ; - 每一轮循环,不需要重算 Cholesky 分解,基于上一轮的
,可快速求出所有 的 Cholesky 分解,从而快速算出所有 的行列式。
DPP 的拓展
首先,在 MMR 中介绍的滑动窗口同样可以用于 DPP :
- 相似地, 随着集合
的增大,其中相似物品越来越多,物品向量会趋于线性相关。 - 此时,行列式
会坍缩到零,对数就会趋于负无穷,DPP 算法失效。 - 故设置一个滑动窗口
,约束所选物品不与窗口内物品相似,允许与更早的物品相似。用 代替公式中的 。基于贪心算法求解公式,得到使用滑动窗口的 DPP 算法公式:$$\operatorname{argmax}{i \in R}\left{\theta \cdot \operatorname{reward}+(1-\theta) \cdot \log \left(\operatorname{det}\left(A_{W \cup{i}}\right)\right)\right}$$ 同样,也可以对 DPP 添加规则约束: - 贪心算法每轮从
中选出一个物品:$$\operatorname{argmax}{i \in R}\left{\theta \cdot \operatorname{reward}+(1-\theta) \cdot \log \left(\operatorname{det}\left(A_{W \cup{i}}\right)\right)\right}$$ - 用规则排除掉
中的部分物品,得到子集 ,然后求解:$$\operatorname{argmax}{i \in R^{\prime}}\left{\theta \cdot \operatorname{reward}+(1-\theta) \cdot \log \left(\operatorname{det}\left(A_{W \cup{i}}\right)\right)\right}$$
本章小结
本章主要介绍推荐系统链路中的最后一环“重排”。实际上重排是对推荐系统中多样性的考察,多样性更能体现用户的个性化。
一般来说,多样性是通过物品相似度来度量的,而物品相似度可以通过物品属性标签或者物品向量表征来度量。因为小红书的笔记天生包括文字和图片,所以小红书常用 CV 和 NLP 模型提取图片和文字特征向量;因为文字和图片相关性高,所以模型预训练使用 CLIP 方法,无需人工标注使用成对的文字图片组合训练。
推荐系统中希望提高曝光物品的多样性,也就是尽量使得物品之间两两不相似。所以在精排和粗排后都有后处理,目的在于对排序结果进行调整,要求物品在兴趣分数高的同时具有较好的多样性。所以,本章后续介绍了两种提升多样性的算法。
第一种 Maximal Marginal Relevance(MMR)多样性算法 来源于搜索排序,使用相关性进行排序。MMR 的基本思想就是从全集(未选中)中选择兴趣分数和多样性(物品相似度)加权分高的物品,放到选中集中,保证所选物品在兴趣分数高的同时与选中集中的物品相似度低。
第二种行列式点过程 (Determinantal Point Process, DPP) 是一种经典的机器学习方法,目标就是如何从一个集合中选出多样化的物品,与重排的目标契合。它的基本思想就是在 MMR 的基础上使用物品向量组成的超平行体体积替换物品相似度的度量,实际应用中,使用物品向量组成的矩阵行列式来度量更为方便简单。同时 DPP 的提出者给出了一种使用 Cholseky 分解的快速求解方法,也是该论文的主要贡献所在。
以上的多样性算法都存在一个通病,当被选取集合越来越大时,待选物品与该集合的相似度的最值越来越高趋近于
在实际应用中,多样性算法还需要根据业务需求设置规则约束。规则约束基本目标是对于笔记、广告、营销卡片等的重复出现做了限制。具体应用时,需要先通过规则约束过滤一遍未选中集合,再用该集合参与多样性算法进行物品的筛选。